ggplot()+
geom_point(aes(Petal.Width, Sepal.Width), iris)+
theme_bw()+
theme(panel.margin=grid::unit(0, "lines"))+
facet_grid(. ~ Species)Annexe A — Techniques de programmation pour la visualisation
Cette annexe décrit plusieurs techniques de programmation R qui sont utiles pour créer des animints.
A.1 Les facettes économes en espace
Pour mettre l’accent sur les données graphiques dans les ggplots à facettes, éliminez l’espace entre les facettes à l’aide de l’idiome suivant.
Cet idiome se compose de trois parties :
-
panel.margin=0élimine l’espace entre les panneaux. -
theme_bwactive un thème noir et blanc (bordures de panneaux noires et arrière-plans de panneaux blancs). Ceci est nécessaire pour voir les limites entre les panneaux, puisque la fonction par défaut de ggplottheme_greyutilise des fonds de panneaux gris et pas de bordures de panneaux. -
facet_*crée un ggplot multi-panneaux.
Notez que nous utilisons l’unité de grille lines qui correspond à la hauteur d’une ligne de texte à la taille par défaut. C’est la seule unité de grille qu’animint sait traduire. Il n’est pas recommandé d’utiliser d’autres unités telles que cm.
A.2 Liste des tableaux de données
Le tableau de données est très utile pour créer des visualisations de données interactives d’une complexité arbitraire. La forme générale ressemble à
library(data.table)
outer.data.list <- list()
inner.data.list <- list()
for(outer in outer.vec){
outer.dt <- computeOuter(outer)
outer.data.list[[paste(outer)]] <- data.table(outer, outer.dt)
for(inner in inner.vec){
inner.dt <- computeInner(outer.dt, inner)
inner.data.list[[paste(outer, inner)]] <-
data.table(outer, inner, inner.dt)
}
}
outer.data <- do.call(rbind, outer.data.list)
inner.data <- do.call(rbind, inner.data.list)Quelques commentaires :
- La première partie de l’idiome consiste à initialiser des listes vides. Ici, il y en a deux,
outer.data.listetinner.data.list. Toutefois, il peut y en avoir autant que nécessaire. - La deuxième partie de l’idiome est un tas de boucles for imbriquées qui assignent des tableaux de données aux éléments de ces listes.
- Des fonctions comme
computeOuteretcomputeInnerpeuvent être utilisées, ou vous pouvez simplement effectuer les calculs directement dans la boucle for. - Pour que votre code soit aussi rapide que possible, utilisez les opérations matrice-vecteur ou vecteur-scalaire dans la boucle for la plus interne. Si vous n’effectuez que des opérations scalaires-scalaires dans votre boucle for interne, vous pouvez certainement améliorer les performances de votre code en supprimant cette boucle for et en réécrivant le calcul en termes d’opérations vectorielles-scalaires.
-
paste()est utilisée pour créer un nom pour ledata.tabledans la liste de résultats. En principe, on peut utiliser soitdata.frame, soitdata.table, mais dans la pratiquedata.tableest souvent beaucoup plus rapide lors de la dernière étape de combinaison. - La dernière partie de l’idiome utilise
do.callavecrbindpour combiner les tableaux de données stockés au cours des boucles for.
A.3 addColumn then facet
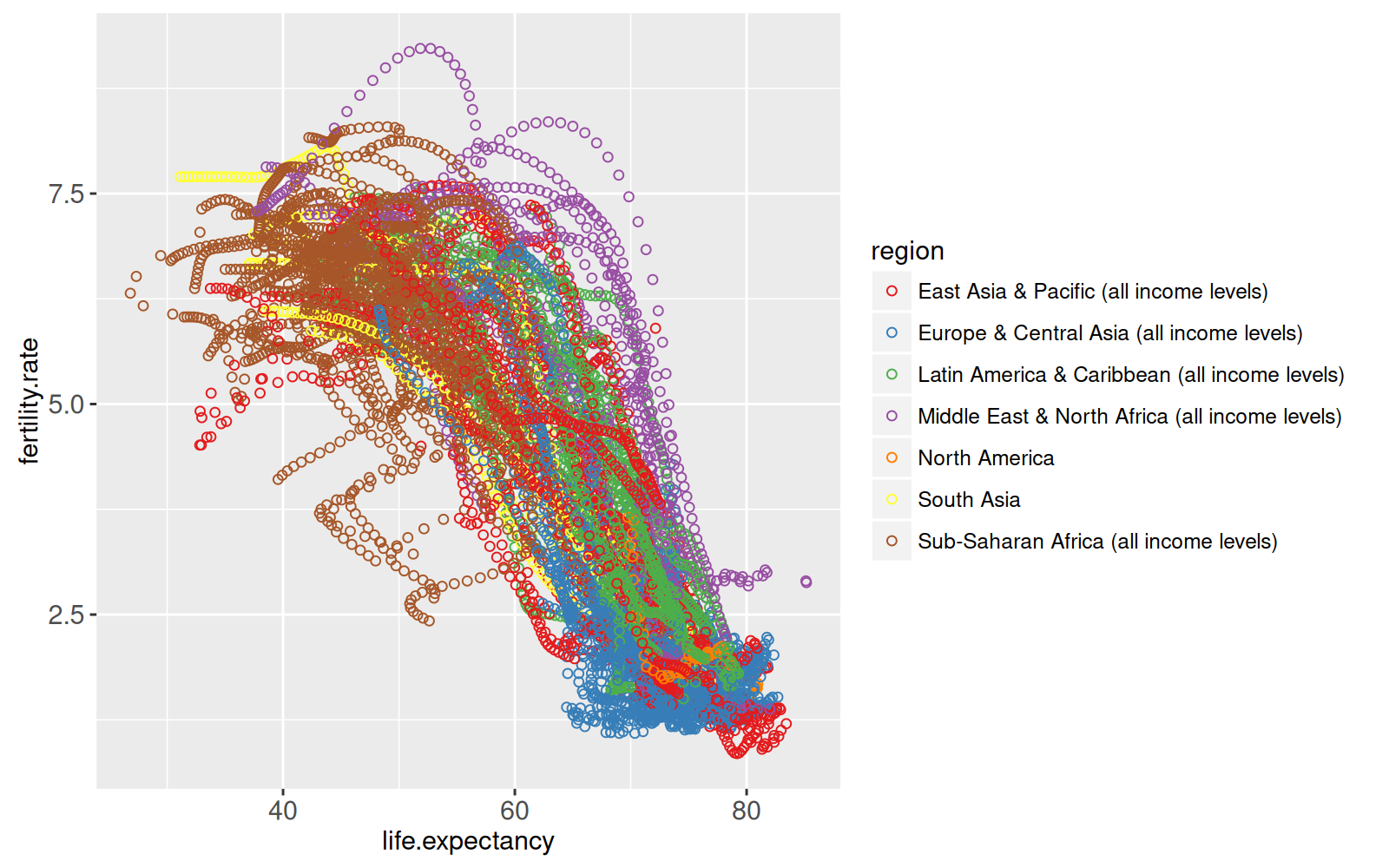
Cet idiome est utile pour créer des ggplots multi-panneaux avec des axes alignés. Tout d’abord, définissez une fonction qui prend en entrée un tableau de données et une ou plusieurs valeurs qui seront utilisées pour ajouter des facteurs à ce tableau de données.
addColumn <- function(df, time.period)data.frame(
df, time.period=factor(time.period, c("1975", "1960-2010")))
animint(
ggplot()+
geom_point(aes(
x=life.expectancy, y=fertility.rate, color=region),
data=addColumn(WorldBank1975, "1975"))+
geom_path(aes(
x=life.expectancy, y=fertility.rate, color=region,
group=country),
data=addColumn(WorldBankBefore1975, "1975"))+
geom_line(aes(
x=year, y=fertility.rate, color=region, group=country),
data=addColumn(WorldBank, "1960-2010"))+
facet_grid(. ~ time.period, scales="free")+
xlab(""))Notez que scales="free" et xlab("") sont utilisés car les axes x ont maintenant des unités très différentes (année et espérance de vie).
A.4 Légendes de couleurs manuelles
On peut utiliser scale_color_manual() et scale_fill_manual() pour préciser les couleurs dans les légendes pour aes(color) et aes(fill). En règle générale, nous choisissons l’une des palettes ColorBrewer :
RColorBrewer::display.brewer.all()
Par exemple, pour obtenir le code R de la palette Set1, nous pouvons écrire
dput(RColorBrewer::brewer.pal(7, "Set1"))c("#E41A1C", "#377EB8", "#4DAF4A", "#984EA3", "#FF7F00", "#FFFF33",
"#A65628")Nous pouvons ensuite copier ce code R depuis le terminal et le coller dans notre éditeur de texte
East Asia & Pacific (all income levels)
"#E41A1C"
Europe & Central Asia (all income levels)
"#377EB8"
Latin America & Caribbean (all income levels)
"#4DAF4A"
Middle East & North Africa (all income levels)
"#984EA3"
North America
"#FF7F00"
South Asia
"#FFFF33"
Sub-Saharan Africa (all income levels)
"#A65628" Nous pouvons ensuite l’utiliser avec scale_color_manual().
library(animint2)
ggplot()+
scale_color_manual(values=region.colors)+
geom_point(aes(
x=life.expectancy, y=fertility.rate, color=region),
data=WorldBank)Warning: Removed 1490 rows containing missing values (geom_point).