if(!requireNamespace("animint2"))install.packages("animint2")Loading required namespace: animint2Dans ce chapitre, nous expliquons la grammaire des graphiques, un modèle puissant pour décrire une vaste gamme de visualisations de données. Après avoir lu ce chapitre, vous serez en mesure :
animint2;
animint2;
La plupart des systèmes d’analyse de données offrent des outils de création de graphiques pour visualiser les tendances des données. Les systèmes les plus anciens proposent des fonctions très générales permettant de tracer les éléments de base d’un graphique, tels que des lignes et des points (par exemple, les packages graphics et grid dans R). Lorsqu’il recourt à l’un de ces systèmes généraux, l’utilisateur doit assembler lui-même les composantes pour obtenir un graphique significatif et interprétable. L’avantage de ces systèmes réside dans le peu de limites imposées aux types de graphiques qui peuvent être créés. Leur principal inconvénient est qu’ils ne fournissent généralement pas de fonctions pour automatiser les tâches courantes (axes, panneaux, légendes).
Pour remédier aux inconvénients de ces systèmes, des packages de visualisation tels que lattice ont été développés (Sarkar, 2008). Ils disposent de plusieurs types de graphiques prédéfinis et fournissent une fonction dédiée à la création de chacun d’eux. Par exemple, lattice offre la fonction bwplot pour concevoir des diagrammes en boîte et des boîtes à moustaches. L’avantage de ces systèmes est qu’ils facilitent grandement la création de graphiques complets avec légendes et panneaux. Par contre, ils proposent un ensemble de modèles de graphiques prédéfinis, ce qui complique la création de graphiques plus complexes.
Les nouveaux systèmes basés sur la grammaire des graphiques se situent entre ces deux extrêmes. Leland Wilkinson a proposé la grammaire des graphiques pour décrire et créer un grand éventail de graphiques (Wilkinson, 2005). Hadley Wickham implémente ultérieurement plusieurs idées de la grammaire des graphiques dans le package R ggplot2 (Wickham, 2009). Le package ggplot2 présente plusieurs avantages par rapport aux systèmes précédents :
lattice, ggplot2 impose peu de limites aux types de graphiques qui peuvent être créés (il n’y a pas de types de graphiques prédéfinis).
lattice, ggplot2 permet d’inclure facilement des éléments de graphique courants, tels que des axes, des panneaux et des légendes.
ggplot2 est basé sur la grammaire des graphiques, il est nécessaire de mapper explicitement les variables de données aux propriétés visuelles. Plus loin dans ce chapitre, nous expliquerons comment ce mappage permet la création d’esquisses qui peuvent être directement traduites en code R.Enfin, tous les systèmes évoqués précédemment sont destinés à la création de graphiques statiques, qui peuvent être visualisés aussi bien sur un écran d’ordinateur que sur du papier. Cependant, le sujet principal de ce manuel est animint2, un package R pour les graphiques interactifs. Contrairement aux graphiques statiques, les graphiques interactifs sont conçus pour être visualisés sur un ordinateur équipé d’une souris et d’un clavier pour interagir avec le graphique. Étant donné que de nombreux concepts des graphiques statiques sont également utiles dans les graphiques interactifs, le package animint2 est implémenté en tant que fork du package ggplot2. Dans ce chapitre, nous présenterons les principales caractéristiques de ggplot2 qui seront également utiles pour la conception de graphiques interactifs dans les chapitres suivants.
En 2013, Toby Dylan Hocking et ses étudiants ont créé le package animint, qui dépend du package ggplot2. Cependant, de 2014 à 2017, ggplot2 a introduit de nombreux changements incompatibles avec la grammaire interactive du package animint, ce qui a conduit en 2018, à la création du package animint2 qui copie les parties pertinentes du package ggplot2. Désormais, animint2 peut être utilisé sans que ggplot2 soit installé. Il est en fait conseillé d’utiliser library(animint2) sans utiliser library(ggplot2). On peut cependant utiliser animint2 avec des packages qui importent ggplot2 (sans l’attacher). À titre d’exemple, voir le chapitre 16 qui utilise le package penaltyLearning (lequel importe ggplot2).
Pour installer la dernière version de animint2 à partir du dépôt CRAN :
if(!requireNamespace("animint2"))install.packages("animint2")Loading required namespace: animint2Pour installer une version de développement encore plus récente de animint2 depuis GitHub :
if(!requireNamespace("animint2")){
if(!requireNamespace("remotes"))install.packages("remotes")
remotes::install_github("animint/animint2")
}Une fois que vous avez installé animint2, vous pouvez charger et attacher toutes ses fonctions exportées via :
Dans cette section, nous expliquons comment traduire une esquisse de graphique en code R. Dans ce manuel, nous utilisons le mot « esquisse » dans le sens de « Première forme, traitée à grands traits et généralement en dimensions réduites, de l’œuvre projetée » (Larousse). Nous vous présenterons souvent l’esquisse dessinée à la main du graphique à créer, avant d’écrire le code nécessaire. Chaque esquisse comportera certains éléments qui nous permettront d’écrire facilement le code correspondant. Nous vous encourageons à faire vos propres esquisses dans un cahier ou sur un tableau avant d’écrire le code du graphique que vous voulez créer. Pour notre exemple, nous utilisons un ensemble de données de la Banque mondiale. Commençons par charger et examiner le nom des colonnes.
if(!requireNamespace("animint2fr")){
if(!requireNamespace("remotes"))install.packages("remotes")
remotes::install_github("animint/animint2fr")
}Loading required namespace: animint2fr [1] "iso2c" "country"
[3] "year" "fertility.rate"
[5] "life.expectancy" "population"
[7] "GDP.per.capita.Current.USD" "15.to.25.yr.female.literacy"
[9] "iso3c" "region"
[11] "capital" "longitude"
[13] "latitude" "income"
[15] "lending" "Region"
[17] "région" "espérance.de.vie"
[19] "taux.de.fertilité" "année"
[21] "pays" "PIB.par.habitant.USD"
[23] "alphabétisation" "revenu" On voit 24 noms ci-dessus. Le jeu de données BanqueMondiale comprend des mesures telles que le taux de fertilité et l’espérance de vie pour chaque pays pour la période 1960-2010. Pour simplifier les sorties ci-dessous, nous considérons seulement le sous-ensemble pertinent pour les visualisations :
région pays année taux.de.fertilité espérance.de.vie
13032 Afrique subsaharienne Zimbabwe 2006 3.551 44.70178
13033 Afrique subsaharienne Zimbabwe 2007 3.491 45.79707
13034 Afrique subsaharienne Zimbabwe 2008 3.428 47.07061
13035 Afrique subsaharienne Zimbabwe 2009 3.360 48.45049
13036 Afrique subsaharienne Zimbabwe 2010 3.290 49.86088
13037 Afrique subsaharienne Zimbabwe 2011 3.219 51.23644
population revenu
13032 12724308 Revenu bas
13033 12740160 Revenu bas
13034 12784041 Revenu bas
13035 12888918 Revenu bas
13036 13076978 Revenu bas
13037 13358738 Revenu basdim(banque_mondiale)[1] 9852 7Le code ci-dessus imprime les dernières lignes, ainsi que les dimensions (lignes 9852 et colonnes 7) du tableau de données. Supposons que nous voulions voir s’il existe une relation entre l’espérance de vie et le taux de fertilité. Nous pourrions fixer une année, puis utiliser ces deux variables de données dans un nuage de points. L’esquisse ci-dessous contient les principaux éléments de cette visualisation de données :
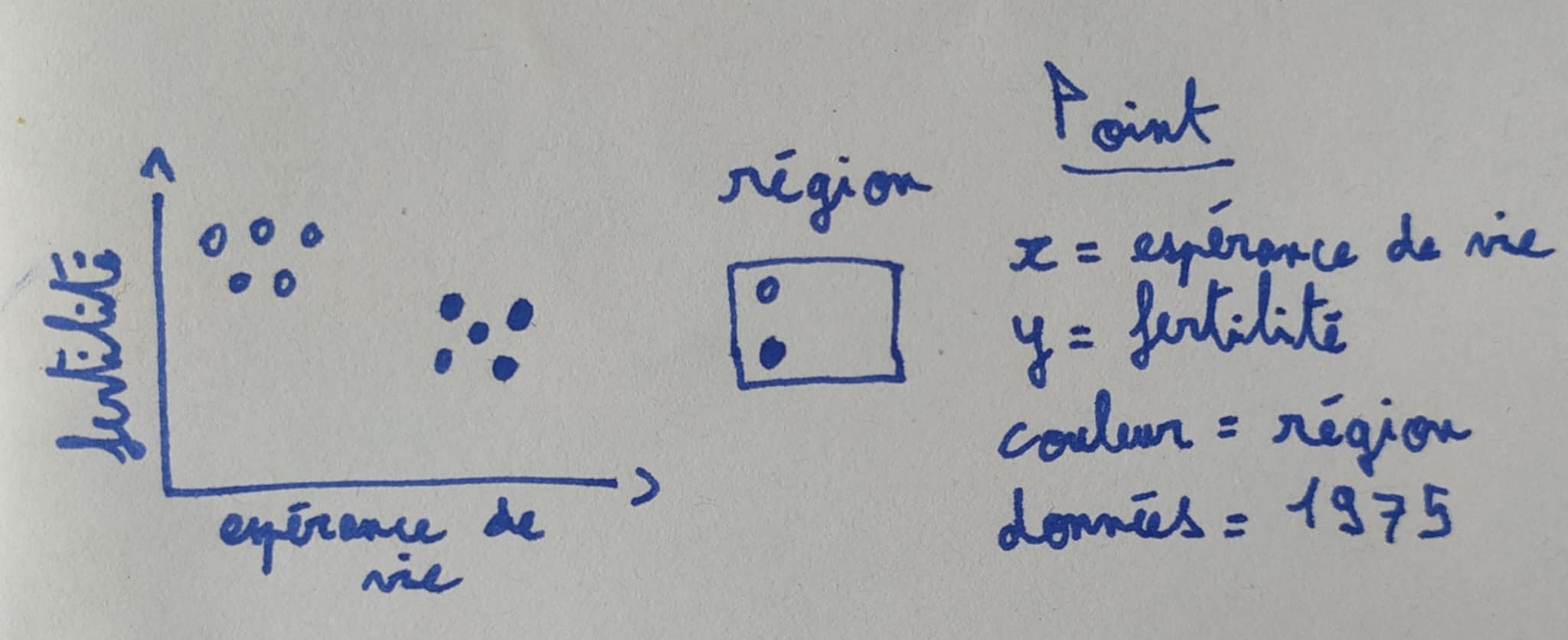
L’esquisse ci-dessus montre l’espérance de vie sur l’axe horizontal (x), le taux de fertilité sur l’axe vertical (y) et une légende pour la région. Ces éléments de l’esquisse peuvent être directement traduits en code R à l’aide de la méthode suivante. Tout d’abord, nous devons construire un tableau de données comportant une ligne par pays pour l’année 1975, et des colonnes nommées espérance.de.vie, taux.de.fertilité, et région. Le jeu de données banque_mondiale possède déjà ces colonnes, il suffit donc de considérer le sous-ensemble pour 1975 :
région pays année taux.de.fertilité
11623 Asie de l'Est et Pacifique Vanuatu 1975 5.929
11676 Asie de l'Est et Pacifique Samoa 1975 5.237
12524 Moyen-Orient et Afrique du Nord Yémen, Rép. du 1975 8.089
12683 Afrique subsaharienne Afrique du Sud 1975 5.251
12895 Afrique subsaharienne Zambie 1975 7.435
13001 Afrique subsaharienne Zimbabwe 1975 7.395
espérance.de.vie population revenu
11623 55.47998 99879 Revenu moyen bas
11676 57.46951 151383 Revenu moyen bas
12524 43.40459 6676714 Revenu moyen bas
12683 54.57920 24728000 Revenu moyen élevé
12895 51.04137 4963655 Revenu moyen bas
13001 56.71702 6170266 Revenu basLe code ci-dessus imprime les dernières lignes en 1975, une ligne par pays. L’étape suivante consiste à utiliser les notes de l’esquisse pour coder un ggplot avec aes() qui établit la correspondance entre variables et propriétés visuelles :
(nuage_de_points <- ggplot()+
geom_point(
mapping=aes(x=espérance.de.vie, y=taux.de.fertilité, color=région),
data=banque_mondiale_1975))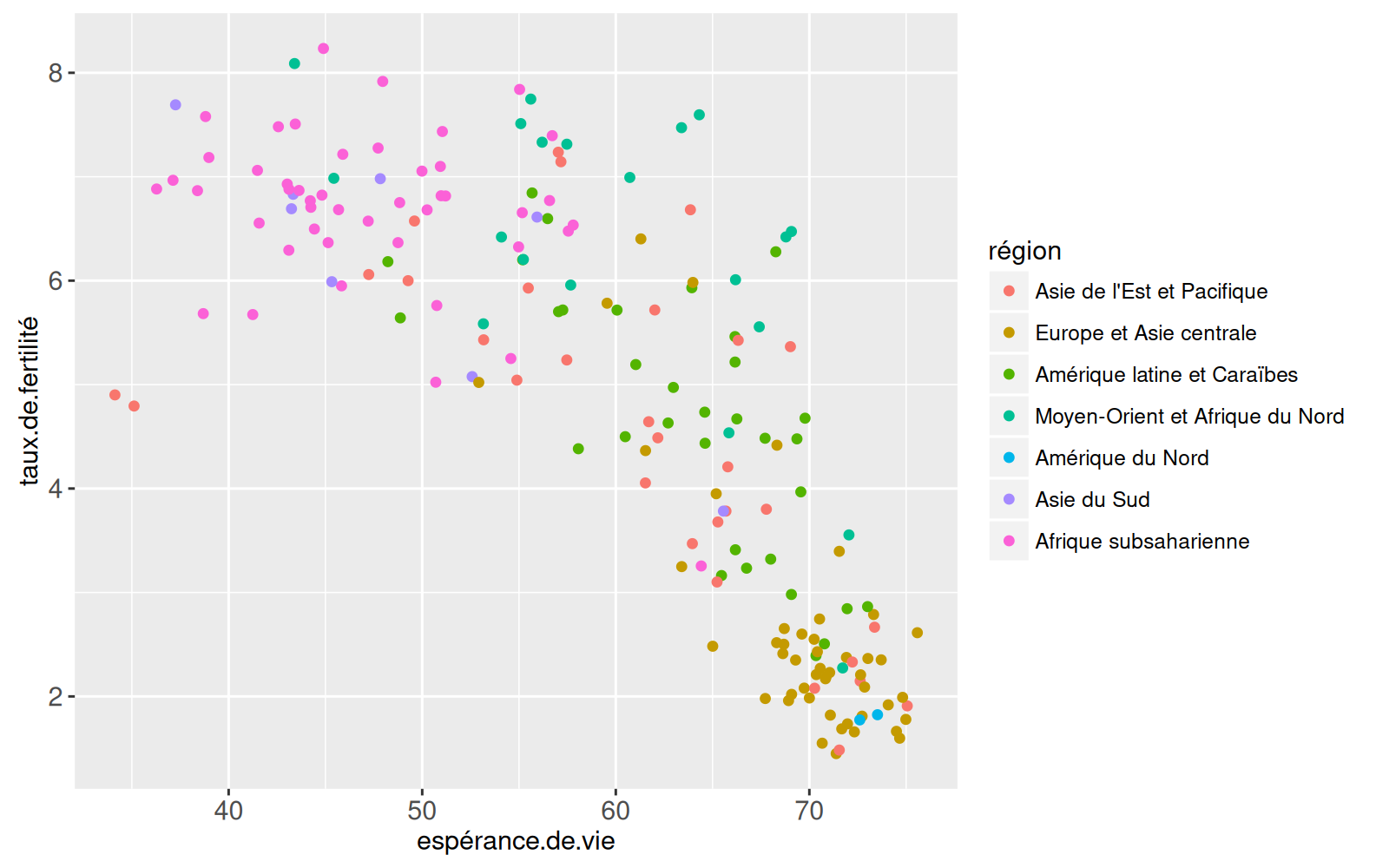
La fonction aes() est appelée avec les noms des propriétés visuelles (x, y, color) et les valeurs des variables de données correspondantes (espérance.de.vie, taux.de.fertilité, région). Cette correspondance est appliquée aux variables du tableau de données banque_mondiale_1975, afin de créer les propriétés du geom_point. Le ggplot a été sauvegardé dans une variable nommée nuage_de_points qui, lorsqu’imprimée sur la ligne de commande R, affiche le graphique sur un périphérique graphique. Notez que nous avons automatiquement une légende région en couleur.
Cette section explique comment animint2 peut être utilisé pour afficher des ggplots sur des pages web. Le ggplot de la section précédente peut être affiché avec animint2, en utilisant la fonction animint :
animint(nuage_de_points)Lorsqu’on le visualise dans un navigateur web, le graphique ressemble aux versions statiques produites par les périphériques graphiques R standard, sauf pour la légende, qui est interactive : en cliquant sur celle-ci, les points de cette couleur sont cachés ou affichés. À l’interne, la fonction animint() crée une liste de classe animint, puis R exécute la fonction print.animint() grâce au système d’objets S3. La fonction animint2dir() est appelée pour compiler la liste en un dossier de fichiers de données (CSV) et de codes (HTML, JavaScript) affichables dans un navigateur web. Dans RStudio, vous devriez voir le graphique s’afficher sous l’onglet « visualiseur ». Vous pouvez configurer le navigateur d’affichage avec l’option browser, par exemple : options(browser="firefox"). Lors de l’exécution du code ci-dessus, si l’animint ne s’affiche pas dans votre navigateur web pour une raison quelconque (par exemple, si vous voyez une page web vierge), veuillez consulter notre FAQ.
Exercices: modification du contenu du aes() du ggplot, puis création d’une nouvelle visualisation.
revenu dans aes(color) ou aes(fill)pour obtenir une légende interactive.population et log10(population) sur x ou y, vous constaterez que la transformation logarithmique fonctionne bien pour cette variable (population varie de plusieurs ordres de grandeur).aes(size=log10(population)); vous obtiendrez une légende quantitative, qui ne sera pas interactive.population, il faudra discrétiser la variable. Créez une nouvelle variable discrète log10pop avec définition paste(round(log10(population))). Si vous utilisez aes(size=log10pop) vous obtiendrez une légende qualitative interactive.Dans ggplot, nous utilisons le mot « couche » comme synonyme de « geom », par exemple geom_point que nous avons utilisé ci-dessus. D’autres geoms existent, tels que geom_line et geom_path qui s’utilisent pour dessiner des courbes. On appelle un graphique « multicouche » lorsqu’on utilise plusieurs geoms dans le même graphique, dessinés les uns sur les autres. Cette approche s’avère utile pour afficher plusieurs geoms ou ensembles de données dans le même graphique. Considérons par exemple l’esquisse suivante qui ajoute une couche de geom_path à la visualisation de données précédente :

Il faut remarquer que l’esquisse ci-dessus comprend deux geoms différents (point et path). Les deux geoms partagent une définition commune des éléments x, y, et color, mais s’appliquent à des ensembles de données différents. De plus, le geom_path() contient group=pays, ce qui signifie qu’il faut dessiner une courbe pour chaque valeur de pays.
Nous traduisons cette esquisse en code R :
Dans le code ci-dessus, nous créons d’abord un nouveau jeu de données banque_mondiale_avant_1975, puis nous ajoutons un geom_path au nuage_de_points ce qui donnne gg_deux_couches un ggplot à deux couches. Nous sauvegardons ensuite la valeur rendue par l’appel à animint() dans l’objet vis.deux.couches, qu’on imprime pour l’afficher. Dans ce manuel, nous utiliserons souvent des noms de variables commençant par vis pour désigner les objets de classe "animint", qui sont en fait des listes de ggplots et d’options.
Le graphique ci-dessus est une visualisation de données à deux couches :
geom_point montre l’espérance de vie, le taux de fertilité et la région de tous les pays en 1975;
geom_path montre les mêmes variables pour les cinq années précédentes.L’ajout de geom_path montre l’évolution des pays au fil du temps. Pour la plupart des pays, les données se sont déplacées vers la droite et vers le bas, ce qui indique une espérance de vie plus élevée et un taux de fertilité plus faible. Il y a cependant quelques exceptions. Par exemple, les deux pays d’Asie de l’Est situés en bas à gauche ont vu leur espérance de vie diminuer au cours de cette période. Par ailleurs, certains pays ont enregistré une hausse de leur taux de fertilité.
Exercice: essayez de remplacer la légende région par une légende revenu. Indice : vous devez utiliser la même spécification aes(color=revenu) pour tous les geoms. Vous pouvez utiliser scale_color_manual avec une palette de couleurs séquentielle. Pour plus de détails, consulter RColorBrewer::display.brewer.all(type="seq") et lire l’annexe.
Pouvons-nous ajouter le nom des pays à la visualisation de données? Ci-dessous, nous ajoutons une autre couche avec une étiquette de texte pour chaque pays :
Cette visualisation n’est pas très facile à lire, car il y a beaucoup d’étiquettes de texte qui se chevauchent. La légende interactive des régions aide un peu, puisqu’elle permet à l’utilisateur de masquer les données des régions sélectionnées. Cependant, il serait préférable que l’utilisateur puisse afficher et masquer individuellement le texte pour chaque pays. Ce type d’interaction s’obtient grâce aux mots-clés showSelected et clickSelects que nous expliquons dans les chapitres 3 et 4.
Pour l’instant, passons à une des grandes forces de animint : la visualisation de données à l’aide de plusieurs graphiques interconnectés.
L’utilisation de plusieurs ggplots est utile lorsqu’on souhaite présenter plusieurs jeux de données, ou plusieurs façons de regarder un seul jeu de données. Ce type de visualisation comporte généralement au moins deux ggplots :
Prenons l’exemple d’une visualisation comportant deux graphiques : une série temporelle avec les données de la Banque mondiale de 1960 à 2010 (sommaire) et un nuage de points avec les données de 1975 (détails). Nous esquissons ci-dessous le graphique des séries temporelles :
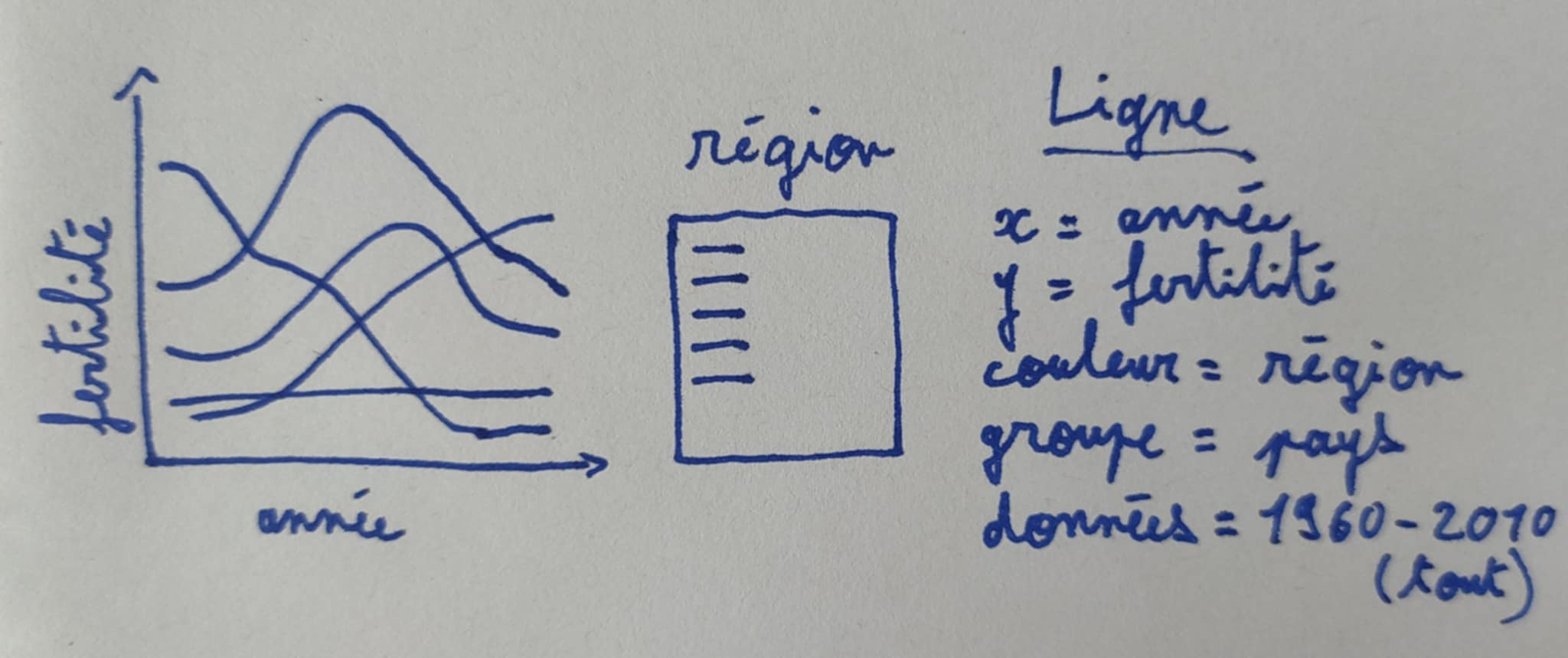
Notez que l’esquisse ci-dessus peut être directement traduite dans le code R ci-dessous. Nous copions ensuite la visualisation existante (vis.deux.couches), puis nous ajoutons un ggplot dans un nouvel élément nommé timeSeries :
Il en résulte une liste nommée de deux éléments (tous deux sont des ggplots de classe gganimint) :
summary(vis.deux.graphes) Length Class Mode
plot1 9 gganimint list
timeSeries 9 gganimint listOn peut imprimer ou afficher cette liste de visualisation de données en tapant son nom. Puisque la liste contient deux ggplots, animint2 affiche la visualisation sous la forme de deux graphiques liés :
vis.deux.graphesLa visualisation ci-dessus contient deux ggplots, qui mappent chacun différentes variables de données sur le plan horizontal x. La série temporelle utilise aes(x=année) et montre un résumé des valeurs du taux de fertilité pour toutes les années. Le nuage de points utilise aes(x=espérance.de.vie) et montre les détails de la relation entre le taux de fertilité et l’espérance de vie en 1975.
Essayez de cliquer sur une entrée de légende dans le nuage de points ou dans la série temporelle ci-dessus. Vous devriez voir les données et les légendes des deux graphiques se mettre à jour simultanément. Étant donné que aes(color=région) a été défini pour les deux graphiques, animint crée une seule variable de sélection partagée appelée région. Cliquer sur l’une des légendes a pour effet de mettre à jour l’ensemble des régions sélectionnées, animint actualise donc les légendes et les données dans les deux graphiques en conséquence. Il s’agit du mécanisme principal utilisé par animint pour créer des visualisations de données interactives avec des graphiques liés, nous en discuterons plus en détail dans les deux prochains chapitres.
Exercice: utilisez animint pour créer une visualisation de données avec trois graphiques, en créant une liste avec trois ggplots. Par exemple, vous pouvez ajouter une série temporelle d’une autre variable de données, comme espérance.de.vie ou population.
Notez que les deux ggplots mappent la variable taux.de.fertilité sur l’axe y. Cependant, comme il s’agit de deux graphiques distincts, les plages de leurs axes y sont calculées séparément. Cela signifie que même lorsque les deux graphiques sont affichés côte à côte, les deux axes y ne sont pas exactement alignés. C’est problématique, la visualisation des données serait plus facile à décoder si chaque unité d’espace vertical représentait la même quantité de taux de fertilité. Pour obtenir cet effet, nous utilisons les facettes dans la section suivante.
Un ggplot peut comporter des facettes (panneaux), c’est-à-dire des sous-graphiques présentant un sous-ensemble de données différent. Le terme « facette » fait référence aux fonctions facet_* correspondantes. L’un des principaux atouts des ggplots est qu’il est relativement facile de créer différents types de graphiques avec plusieurs facettes. Les facettes répondent à deux objectifs :
Les facettes sont utiles pour aligner les axes quand on veut afficher différents geoms dans chaque facette. Considérons l’esquisse ci-dessous qui contient un graphique avec deux panneaux :
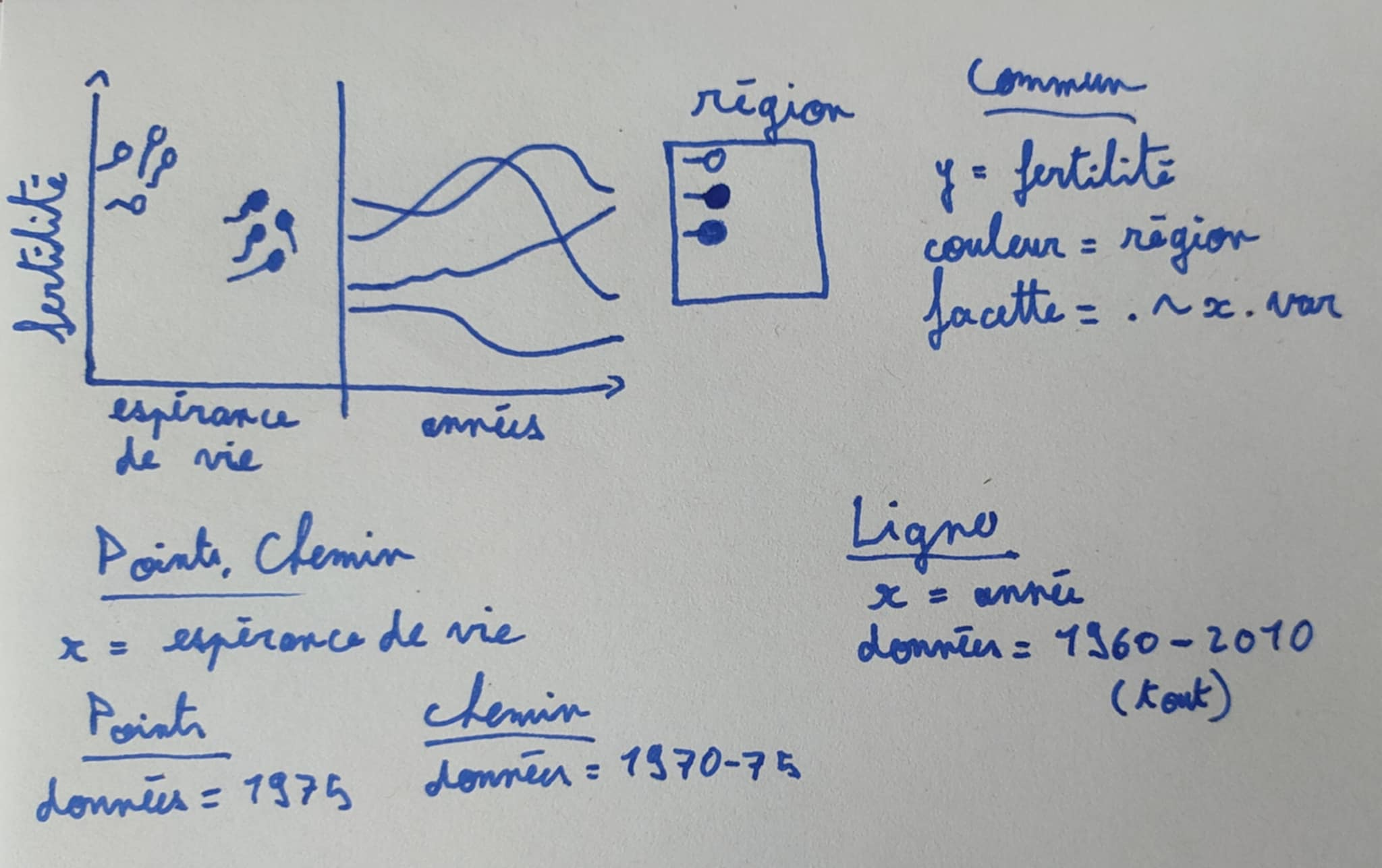
Notez que les deux panneaux tracent des geoms différents, chacun avec son propre aes(). Le geom_point et le geom_path dans le panneau de gauche ont x=espérance.de.vie, tandis que le geom_line du panneau de droite utilise x=année. Notez également que nous avons écrit facet=x.var, nous devons donc ajouter une variable x.var à chacun des trois ensembles de données. Nous traduisons cette esquisse en code R ci-dessous :
add.x.var <- function(df, x.var){
data.frame(df, x.var=factor(x.var, c("espérance de vie", "année")))
}
(vis.aligné <- animint(
scatter=ggplot()+
theme_bw()+
theme_animint(width=600)+
geom_point(aes(
x=espérance.de.vie, y=taux.de.fertilité, color=région),
data=add.x.var(banque_mondiale_1975, "espérance de vie"))+
geom_path(aes(
x=espérance.de.vie, y=taux.de.fertilité, color=région,
group=pays),
data=add.x.var(banque_mondiale_avant_1975, "espérance de vie"))+
geom_line(aes(
x=année, y=taux.de.fertilité, color=région, group=pays),
data=add.x.var(banque_mondiale, "année"))+
xlab("")+
facet_grid(. ~ x.var, scales="free")))La visualisation de données ci-dessus contient un seul ggplot avec deux panneaux et trois couches. Le panneau de gauche montre les geom_point et geom_path et le panneau de droite montre les geom_line. Les panneaux ont un axe commun pour le taux de fertilité, ce qui facilite la comparaison directe entre le geom_line du panneau des séries temporelles et le geom_point et le geom_path du panneau du nuage de points.
La méthode employée ici utilise add.x.var pour ajouter une variable x.var à chaque ensemble de données, puis nous avons utilisé cette variable dans la fonction facet_grid(scales="free"). Nous appelons cette méthode Ajouter une variable ensuite des facettes. Elle est particulièrement utile pour créer une visualisation de données à plusieurs panneaux avec des axes alignés. Ainsi, pour changer l’ordre des panneaux dans la visualisation, il suffit de modifier l’ordre des niveaux de facteurs dans la définition de add.x.var.
Notez également que theme_bw() produit des bordures de panneaux noires et des fonds de panneaux blancs, et que theme(panel.margin=0) pourrait être utilisé pour supprimer l’espacement entre les panneaux. Cette élimination libère de l’espace pour les panneaux, ce qui met l’accent sur les données. Nous appelons cette méthode Les facettes économes en espace, elle est généralement utile dans tout ggplot avec des facettes.
Dans la visualisation ci-dessus, les étiquettes de texte se chevauchent un peu, ce qui peut être corrigé par l’une des méthodes suivantes (exercice pour le lecteur) :
breaks de scale_x_continuous()
theme() et element_text()
theme_animint() voir le chapitre 6 pour plus d’informations.La deuxième raison d’utiliser des graphes avec plusieurs panneaux dans une visualisation de données est de comparer des sous-ensembles d’observations. Cette approche facilite la comparaison entre les sous-ensembles de données et peut être utilisée dans au moins deux situations différentes :
Prenons l’exemple de l’esquisse ci-dessous :
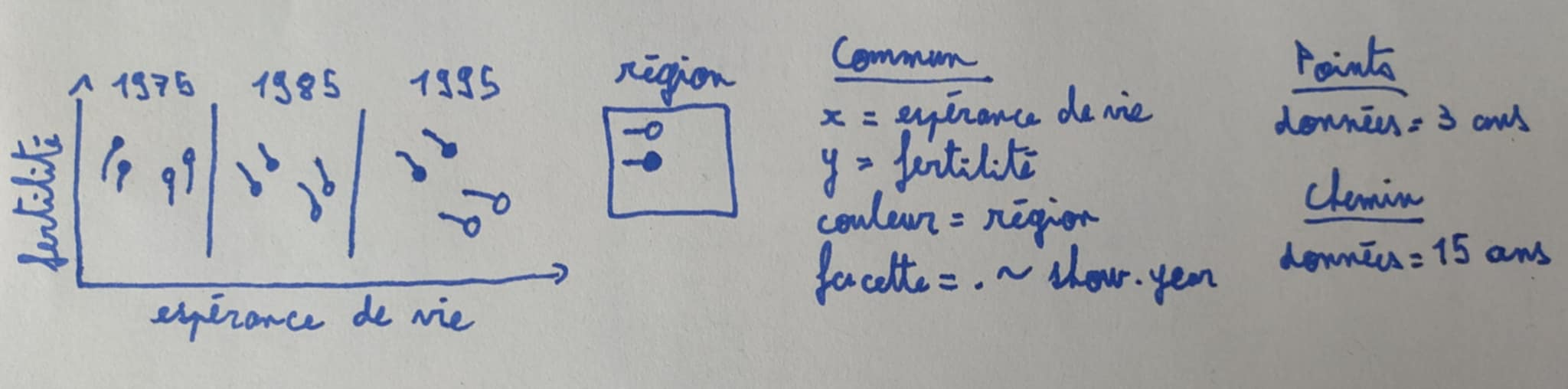
Notez que les trois panneaux tracent les deux mêmes geoms, geom_point et geom_path. Puisque facet=afficher.année et qu’il y a trois panneaux, nous devrons créer des tableaux de données qui auront trois valeurs pour la variable afficher.année. Le geom_point ne contient des données que pour 3 ans, et le tableau geom_path a des données pour 15 ans (mais 3 valeurs de afficher.année). Le code ci-dessous crée ces deux ensembles de données pour 3 années de l’ensemble de données de la Banque mondiale :
afficher.point.list <- list()
afficher.path.list <- list()
for(afficher.année in c(1975, 1985, 1995)){
afficher.point.list[[paste(afficher.année)]] <- data.frame(
afficher.année, subset(
banque_mondiale, année==afficher.année))
afficher.path.list[[paste(afficher.année)]] <- data.frame(
afficher.année, subset(
banque_mondiale,
afficher.année - 5 <= année & année <= afficher.année))
}
afficher.point <- do.call(rbind, afficher.point.list)
afficher.path <- do.call(rbind, afficher.path.list)Nous avons utilisé une boucle for sur trois valeurs de afficher.année, la variable que nous utiliserons plus tard dans facet_grid. Pour chaque valeur de afficher.année nous stockons un sous-ensemble de données sous la forme d’un élément nommé d’une liste. Après la boucle for, nous utilisons do.call avec rbind pour combiner les sous-ensembles de données. Il s’agit d’un exemple de la méthode Liste de tableau de données, utile pour la visualisation interactive :
Ci-dessous, nous appliquons les facettes sur la variable afficher.année pour créer une visualisation de données à trois panneaux :
animint(
scatter=ggplot()+
geom_point(aes(
x=espérance.de.vie, y=taux.de.fertilité, color=région),
data=afficher.point)+
geom_path(aes(
x=espérance.de.vie, y=taux.de.fertilité, color=région,
group=pays),
data=afficher.path)+
facet_grid(. ~ afficher.année)+
theme_bw())La visualisation ci-dessus contient un seul ggplot avec trois facettes. Elle montre une portion plus étendue de l’ensemble des données de la Banque mondiale que les visualisations précédentes qui se limitaient aux données de 1975. Cependant, elle ne montre qu’un sous-ensemble de données relativement restreint. Vous pourriez être tenté d’utiliser un panneau pour afficher chaque année (plutôt que seulement 1975, 1985 et 1995). Sachez toutefois que ce type de visualisation à plusieurs panneaux fonctionne bien seulement s’il y a un nombre limité de sous-ensembles de données. Au-delà d’une dizaine de panneaux, il devient difficile de voir toutes les données simultanément, et donc de faire des comparaisons significatives.
Plutôt que de montrer toutes les données à la fois, nous pouvons créer une visualisation de données animée qui présente à l’observateur différents sous-ensembles de données au fil du temps. Dans le chapitre suivant nous verrons comment le nouveau mot-clé showSelected peut être utilisé pour réaliser une animation, et nous révélerons plus de détails sur cet ensemble de données.
Ce chapitre a présenté les bases de la visualisation de données statiques avec ggplot2. Nous avons montré comment animint peut être utilisé pour afficher une liste de ggplots dans un navigateur web. Nous avons expliqué comment ggplot2 facilite la création de graphiques avec plusieurs couches et plusieurs facettes.
Exercices :
ggplot2 par rapport aux systèmes antérieurs tels que grid et lattice?
vis.alignée, pourquoi est-il important d’utiliser l’argument scales="free"?
vis.alignée nous avons montré un ggplot avec un panneau de nuage de points à gauche et un panneau de séries temporelles à droite. Réalisez une autre version de la visualisation de données avec le panneau des séries temporelles à gauche et le panneau du nuage de points à droite.
vis.alignée le nuage de points affiche le taux de fertilité et l’espérance de vie, mais la série chronologique n’affiche que le taux de fertilité. Créez une variante de la visualisation qui affiche les deux séries temporelles. Indice : utilisez les panneaux horizontaux et verticaux dans facet_grid.
aes(size=population) dans le nuage de points pour indiquer la population de chaque pays. Indice : scale_size_animint(pixel.range=c(5, 10)) signifie que des cercles d’un rayon de 5/10 pixels doivent être utilisés pour représenter la population minimale/maximale.
banque_mondiale dans un panneau distinct. Quelles sont les limites de l’utilisation de graphiques statiques pour visualiser ces données?
vis.alignée en utilisant un système de tracé qui n’est pas basé sur la grammaire des graphiques. Par exemple, vous pouvez utiliser les fonctions du package graphics dans R (plot,points,lines etc.), ou matplotlib en Python. Quels sont les avantages de ggplot2 et de animint?Dans le chapitre 3 nous expliquons le mot-clé showSelected, qui nous permettra de préciser l’interactivité ainsi que l’animation.