Ordre réel
Choix de la dame Lait-thé Thé-lait
Lait-thé 3 1
Thé-lait 1 3Visualisation interactive de données dans R avec animint2
1 Contenu et contexte
![]()
Résumé : Dans la visualisation de données, les graphiques interactifs permettent de cliquer sur des éléments d’un graphique, pour ensuite changer ce qui est affiché dans un autre graphique. Ils sont utiles pour l’enseignement et la recherche, mais ils sont souvent difficiles à créer. Ce livre présente animint2, un package R qui facilite la création des visualisations interactives. Nous présentons d’abord quelques principes fondamentaux pour la visualisation de données ; ensuite, nous donnons quelques exemples avancés. Chaque chapitre présente des codes R et leurs sorties graphiques, avec commentaires pour aider le lecteur à interpréter les graphiques, et à comprendre les codes. Pour faciliter l’utilisation du livre dans un cours de visualisation de données, il y a des exercices à la fin de chaque chapitre.
Remerciements : Ce manuel a été réalisé avec le soutien de la fabriqueREL. Fondée en 2019, la fabriqueREL est portée par divers établissements d’enseignement supérieur du Québec et agit en collaboration avec les services de soutien pédagogique et les bibliothèques. Son but est de faire des ressources éducatives libres (REL) le matériel privilégié en enseignement supérieur au Québec.
Logo de la page couverture : Andrés Henao Florez.
Comité de lecture : Mariano Avino, Guillaume Blanchet, Aurélien Nicosia, Nadia Tahiri.
Traduction : Anna Artiges et Jérémi Lepage.
Révision linguistique : Nadia Fournier.
© Toby Dylan HOCKING.
Pour citer cet ouvrage : Toby Hocking (2026). Visualisation interactive de données dans R avec animint2. Université de Sherbrooke, Département d’informatique. fabriqueREL. Licence CC BY-SA. https://doi.org/10.71892/11143/1448
@book{Hocking2026,
title={Visualisation interactive de données dans R avec animint2},
author={Toby Dylan Hocking},
year={2026},
publisher={Université de Sherbrooke, fabriqueREL, license CC_BY-SA},
url={https://animint-manual-fr.netlify.app},
doi={10.71892/11143/1448}
}
1.1 Informations de publication
Cette section reprend, avec des modifications, l’introduction du livre Méthodes quantitatives en sciences sociales : un grand bol d’R (Philippe et Gelb 2024).
1.1.1 Un manuel sous la forme d’une ressource éducative libre
Pourquoi un manuel sous licence libre ?
Les logiciels libres sont aujourd’hui très répandus. Comparativement aux logiciels propriétaires, l’accès au code source permet à quiconque de l’utiliser, de le modifier, de le dupliquer et de le partager. Le logiciel R est à la fois un langage de programmation et un logiciel libre, sous la licence publique générale (Wikipédia 2025a). Par analogie aux logiciels libres, il existe aussi des ressources éducatives libres (REL) « dont la licence accorde les permissions désignées par les 5R (Retenir — Réutiliser — Réviser — Remixer — Redistribuer) et donc permet nécessairement la modification » (Auteurs-du-site-fabriqueREL 2025). La licence de ce livre, CC BY-SA (figure 1.1), permet donc de :
Retenir, c’est-à-dire télécharger et imprimer gratuitement le livre. Notez qu’il aurait été plutôt surprenant d’écrire un livre payant sur un logiciel libre et donc gratuit. Aussi, nous aurions été très embarrassés que des personnes étudiantes avec des ressources financières limitées doivent payer pour avoir accès au livre, sans pour autant savoir préalablement si le contenu est réellement adapté à leurs besoins.
Réutiliser, c’est-à-dire utiliser la totalité ou une section du livre sans limitation et sans compensation financière. Cela permet ainsi à d’autres personnes enseignantes de l’utiliser dans le cadre d’activités pédagogiques.
Réviser, c’est-à-dire modifier, adapter et traduire le contenu en fonction d’un besoin pédagogique précis, puisqu’aucun manuel n’est parfait, tant s’en faut ! Le livre a d’ailleurs été écrit intégralement dans R avec Quarto. Quiconque peut ainsi télécharger gratuitement le code source du livre, et le modifier à sa guise (voir l’encadré intitulé Suggestions d’adaptation du manuel).
Remixer, c’est-à-dire « combiner la ressource avec d’autres ressources dont la licence le permet aussi pour créer une nouvelle ressource intégrée ».
Redistribuer, c’est-à-dire distribuer, en totalité ou en partie, le manuel ou une version révisée sur d’autres canaux que le site Web du livre (par exemple, sur le site Moodle de votre université) ou en faire une version imprimée.
La licence de ce livre, CC BY-SA (figure 1.1), oblige donc à :
- Attribuer la paternité de l’auteur dans vos versions dérivées, et ajouter une mention concernant les grandes modifications apportées.
- Utiliser la même licence ou une licence similaire à toutes versions dérivées.
1.1.2 Suggestions d’adaptation du manuel
Plusieurs adaptations du manuel sont possibles :
- Conserver uniquement les chapitres sur les méthodes ciblées dans votre cours.
- En faire une version imprimée et la distribuer aux personnes étudiantes.
- Modifier un ou plusieurs chapitres en effectuant les mises à jour directement dans les chapitres.
- Modifier les tableaux et figures.
- Ajouter une série d’exercices.
- Rédiger un nouveau chapitre.
- Toute autre adaptation qui permet de répondre au mieux à un besoin pédagogique.
1.1.3 Un manuel conçu comme un projet collaboratif
Il existe actuellement de nombreuses ressources, surtout en anglais, pour l’apprentissage de la visualisation statique (non interactive) avec la grammaire des graphiques. En français il y a :
- Exploration de données avec R, Chapitre 8 (Ghouch 2021).
- Introduction à R et au tidyverse, Chapitre 8 Visualiser avec ggplot2 (Barnier 2024).
- Stat4230 Graphiques avec ggplot2 en R (Baillargeon 2021).
- Introduction à l’analyse d’enquêtes avec R et RStudio, Introduction à ggplot2, la grammaire des graphiques (Larmarange 2024).
- utilitr, Faire des graphiques avec ggplot2 (Berrard et al. 2024).
Il y a certaines ressources sur R en français qui proposent un chapitre sur la visualisation interactive :
- Les packages
plotlyetshinypour les épidémiologistes (Batra et al. 2026). - Plusieurs packages pour différentes sortes de visualisation (Rouvière 2026).
À notre connaissance, ce projet constitue le premier manuel numérique en français sur la visualisation de données interactive. Ceci est une traduction du livre en anglais (Hocking 2026). Nous considérons ce livre comme un projet collaboratif visant à mobiliser la communauté universitaire francophone qui enseigne la science de données avec R. Plusieurs raisons motivent cette vision collaborative :
Rien n’est parfait ! Cette première version comprend sûrement des coquilles et certaines sections mériteraient d’être améliorées. Les commentaires et suggestions visant à améliorer son contenu sont les bienvenus.
La table des matières doit être impérativement extensible ! Si vous êtes intéressé(e)s à ajouter un nouveau chapitre ou une partie au livre, nous vous invitons vivement à communiquer avec nous (en utilisant l’option « Signaler un problème ou formuler une suggestion » à droite sur chaque page web).
1.2 Contenu
Ce manuel comporte trois volets que nous présentons dans les sections suivantes.
1.2.1 Extensions animint2 à la grammaire des graphiques
Les sept premiers chapitres fournissent les bases de la visualisation interactive des données avec animint2 et vous devriez les lire dans l’ordre.
Dès la section contexte ci-dessous, ce premier chapitre donne un aperçu de l’analyse et de la visualisation de données. Il apporte le contexte et la base théorique nécessaire à la compréhension des autres chapitres, ce qui sera particulièrement utile aux novices en matière d’analyse de données. Il présente la méthode de prototypage de visualisation des données à l’aide d’esquisses, sans introduire de code R.
À partir du chapitre 2, nous démontrons comment traduire les esquisses de graphiques en code R. Ce chapitre présente les bases de la visualisation de données à l’aide de ggplots et de animint2, et sera une ressource précieuse pour les lecteurs qui n’ont jamais utilisé ggplot2. Nous y expliquons comment générer des ggplots standards sur des pages web en utilisant animint2.
Le chapitre 3 présente showSelected, l’un des deux principaux mots-clés introduits par animint2 pour la conception de visualisation des données interactives. Ce chapitre s’ouvre sur une explication des variables de sélection, qui constituent le mécanisme d’interaction dans animint2. Le chapitre 3 explique ensuite comment le mot-clé showSelected permet de tracer des sous-ensembles de données. Nous expliquons également comment utiliser des transitions graduelles et des animations.
Le chapitre 4 est consacré à clickSelects, l’autre mot-clé important introduit par animint2 pour la conception de visualisation des données interactives. Le mot-clé clickSelects permet à l’utilisateur de modifier une variable de sélection en cliquant directement sur un élément du graphique.
Le chapitre 5 explique différentes façons de partager vos visualisations de données interactives sur le web.
Le chapitre 6 couvre d’autres fonctionnalités de animint2, y compris la manière de définir des hyperliens, des infobulles et toutes les autres nouvelles fonctionnalités qui n’existent pas dans les graphiques statiques de ggplot2.
Le chapitre 7 couvre les limites de l’implémentation actuelle du package R animint2, et propose des solutions de contournement pour certains problèmes courants. De plus, il présente quelques idées d’amélioration, à l’intention de ceux qui souhaiteraient contribuer au développement de animint2.
1.2.2 Exemples
L’ordre de lecture des chapitres suivants n’est pas important, puisqu’ils expliquent comment réaliser des visualisations pour un jeu de données ou un algorithme statistique particulier.
Le chapitre 8 présente une visualisation des données de la Banque mondiale.
Le chapitre 9 présente une visualisation des données provenant de cyclistes de Montréal.
Le chapitre 10 présente une visualisation de l’algorithme des plus proches voisins, inspirée du livre Elements of Statistical Learning (Hastie et al. 2009).
Le chapitre 11 présente une visualisation du Lasso, un modèle d’apprentissage automatique pour la régression régularisée.
Le chapitre 12 présente une visualisation du séparateur à vaste marge (aussi connu sous le nom de « machine à vecteurs de support » ou SVM), un modèle d’apprentissage automatique pour la classification binaire.
Le chapitre 13 présente une visualisation pour la régression de Poisson.
Le chapitre 14 présente une visualisation avec de nombreux sélecteurs, à l’aide de clickSelects et showSelected nommés, dans une visualisation interactive appliquée à un modèle pour la détection de pics.
Le chapitre 15 présente une visualisation de l’algorithme de recherche de racines « root-finding » de Newton.
Le chapitre 16 présente une visualisation d’un modèle de détection de ruptures dans les données séquentielles.
Le chapitre 17 présente une visualisation de l’algorithme d’agrégation « clustering », k-moyennes.
Le chapitre 18 présente une visualisation de l’algorithme de descente de gradient pour l’apprentissage d’un réseau de neurones.
Le chapitre 19 présente une visualisation des probabilités critiques (valeurs-p) d’un test statistique, pour évaluer la significativité des différences entre deux échantillons. Un trop grand nombre de données dans un nuage de points cause de l’occlusion, nous proposons donc une carte thermique reliée à un nuage de points comportant seulement les données sélectionnées.
Le chapitre 20 propose plusieurs visualisations pour comparer différents algorithmes d’apprentissage artificiel, calculé avec le package mlr3.
1.2.3 Annexes
Le glossaire contient l’explication détaillée de plusieurs techniques de programmation R qui sont utiles pour la visualisation.
Le guide de contribution fournit des instructions sur la manière de contribuer à l’amélioration de ce manuel.
1.3 Contexte
L’objectif de ce manuel est d’expliquer l’utilisation d’animint2, un package R pour la visualisation interactive des données. Ce chapitre d’introduction répond aux questions suivantes :
- Que sont les données et comment les analyser ?
- Qu’est-ce que la visualisation des données, et quand est-elle utile pour l’analyse des données ?
- Qu’est-ce que la visualisation des données interactive et dans quelles situations est-elle utile ?
La structure du chapitre est la suivante :
- Qu’est-ce qu’une donnée ?
- Petits ensembles de données – la visualisation des données n’est pas nécessaire.
- Moyens ensembles – la visualisation statique des données est suffisante.
- Grands ensembles - la visualisation interactive est utile.
1.3.1 Qu’est-ce que l’analyse des données ?
Les données sont des éléments d’information enregistrés de manière systématique, que ce soit sur support papier ou informatique. Tout le monde peut créer des données, simplement en consignant méthodiquement des éléments. En général, les données sont créées pour répondre à une question précise et sont organisées en tableaux comportant des lignes pour les observations et des colonnes pour les variables ou différents types d’informations. D’après Larousse, « donnée » désigne la « représentation conventionnelle d’une information en vue de son traitement informatique » (Larousse 2025). Dans le cas de animint2, la représentation conventionnelle est un tableau, dans lequel chaque ligne correspond à une observation, et chaque colonne à une variable. Nous utilisons le terme « ensemble de données » pour désigner un sous-ensemble d’observations/de lignes, ou le tableau de données dans son intégralité.
Il existe de nombreux exemples de données qui pourraient être créées pour répondre à des questions basées sur des expériences quotidiennes :
- Comment la météo de cette année se compare-t-elle à celle des années précédentes ? La quantité de pluie est-elle supérieure ou inférieure à la normale ? Pour répondre à ces questions, nous pourrions créer un tableau de données avec des colonnes pour les mesures des différentes conditions météorologiques (température, précipitations, etc.), ainsi que des colonnes pour la date et l’heure de chaque observation, et une ligne pour chaque observation.
- Quel est l’effet de mon régime alimentaire sur ma santé ? Si vous modifiez votre alimentation, vous pouvez noter ce que vous mangez et comment vous vous sentez après chaque repas dans un tableau de contingence comportant une ligne pour chaque repas et quatre colonnes (date, heure, aliments consommés, effets constatés).
- Ce nouveau traitement contre le cancer du poumon est-il plus efficace que l’ancien ? Le médecin responsable d’un essai clinique répartit au hasard les patients en deux groupes : l’un recevant un nouveau traitement, l’autre l’ancien. Le médecin créerait ensuite un tableau de données comportant une ligne pour chaque patient, et plusieurs colonnes : nombre d’années de tabagisme, type de traitement (nouveau ou ancien), âge au moment du traitement, âge au décès, mesure des marqueurs tumoraux, etc.
Nous définissons l’« analyse des données » comme le processus visant à répondre à ces questions en convertissant le tableau de données brut en d’autres formes plus compréhensibles. Parmi les méthodes d’analyse particulièrement efficaces figure la « visualisation des données », qui cherche à répondre aux questions en transposant un ensemble de données en une image informative. Le terme « visualisation des données » désigne à la fois l’image (également connue sous le nom de graphique, figure, diagramme, graph, plot ou visualisation de données) et le processus de création de l’image.
Il existe de nombreuses façons différentes d’effectuer une analyse de données, et différentes techniques sont nécessaires selon la taille des ensembles de données. Bien que les définitions varient d’un auteur à l’autre, nous adopterons dans ce manuel une classification en trois catégories : petits, moyens et grands ensembles de données. Nous discutons d’abord des petits ensembles de données, pour lesquels la visualisation n’est pas nécessaire.
1.3.2 Analyse des petits ensembles de données sans visualisation
Dans cette section, nous aborderons les « petits ensembles de données » dont la taille restreinte permet une analyse par simple examen du tableau de données. Pour ces ensembles, la visualisation graphique n’est pas nécessaire : la présentation sous forme de tableau est suffisante.
Prenons l’exemple de la célèbre expérience de dégustation du thé conçue par Ronald Fisher (Wikipédia 2025b). Une dame a affirmé pouvoir détecter si le lait d’une tasse de thé avait été ajouté avant ou après le thé. Fisher s’est posé la question suivante : la dame peut-elle vraiment distinguer les deux types de préparation ?
Pour répondre à cette question, Fisher a préparé huit tasses : quatre avec du lait ajouté après le thé, et quatre avec du lait ajouté avant. Il les a ensuite fait goûter à la dame dans un ordre aléatoire en lui demandant d’identifier celles dans lesquelles le lait avait été ajouté après le thé. Selon help(fisher.test) dans R, la dame a correctement identifié trois des quatre tasses. Fisher a ensuite consigné les données suivantes : le nombre total de tasses (8), le nombre de tasses dans lesquelles du lait a été ajouté (4) et le nombre de tasses correctement identifiées (3). Cet ensemble de données peut être visualisé dans R en imprimant un tableau de contingence des données de comptage.
Dans ce cas, l’ensemble de données est suffisamment petit pour que l’on puisse répondre à la question de Fisher en examinant simplement le tableau de données lui-même. Si la dame avait identifié correctement les quatre tasses, la démonstration de ses capacités aurait été très convaincante. Cependant, elle n’a réussi que dans trois cas sur quatre, ce qui est moins concluant.
Le sujet principal de ce manuel est la visualisation des données, et elle n’est pas nécessaire pour des ensembles de données aussi petits. Concentrons-nous plutôt sur les ensembles de données trop volumineux pour être analysés par examen visuel direct du tableau de données.
1.3.3 Analyse des moyens ensembles de données avec des visualisations de données statiques
Pour les ensembles de données de taille moyenne, la simple inspection du tableau de données ne suffit plus pour répondre aux questions posées lors de l’analyse des données. Ces ensembles sont suffisamment volumineux pour nécessiter l’utilisation de la visualisation pour comprendre les données.
Prenons par exemple les données suivantes sur les concentrations de dioxyde de carbone (CO₂) dans l’atmosphère, enregistrées mensuellement de 1959 à 1997 :
year.int month.int mois year.month.POSIXct ppm
1: 1959 1 janvier 1959-01-15 315.42
2: 1959 2 février 1959-02-15 316.31
---
467: 1997 11 novembre 1997-11-15 362.49
468: 1997 12 décembre 1997-12-15 364.34L’impression de ces données sur la ligne de commande R montre qu’il y a 468 lignes/observations au total. Ce nombre n’est pas énorme, mais il est déjà suffisamment important pour qu’une simple inspection du tableau ne permette pas de répondre aux questions posées. Nous allons donc créer une visualisation des données statique.
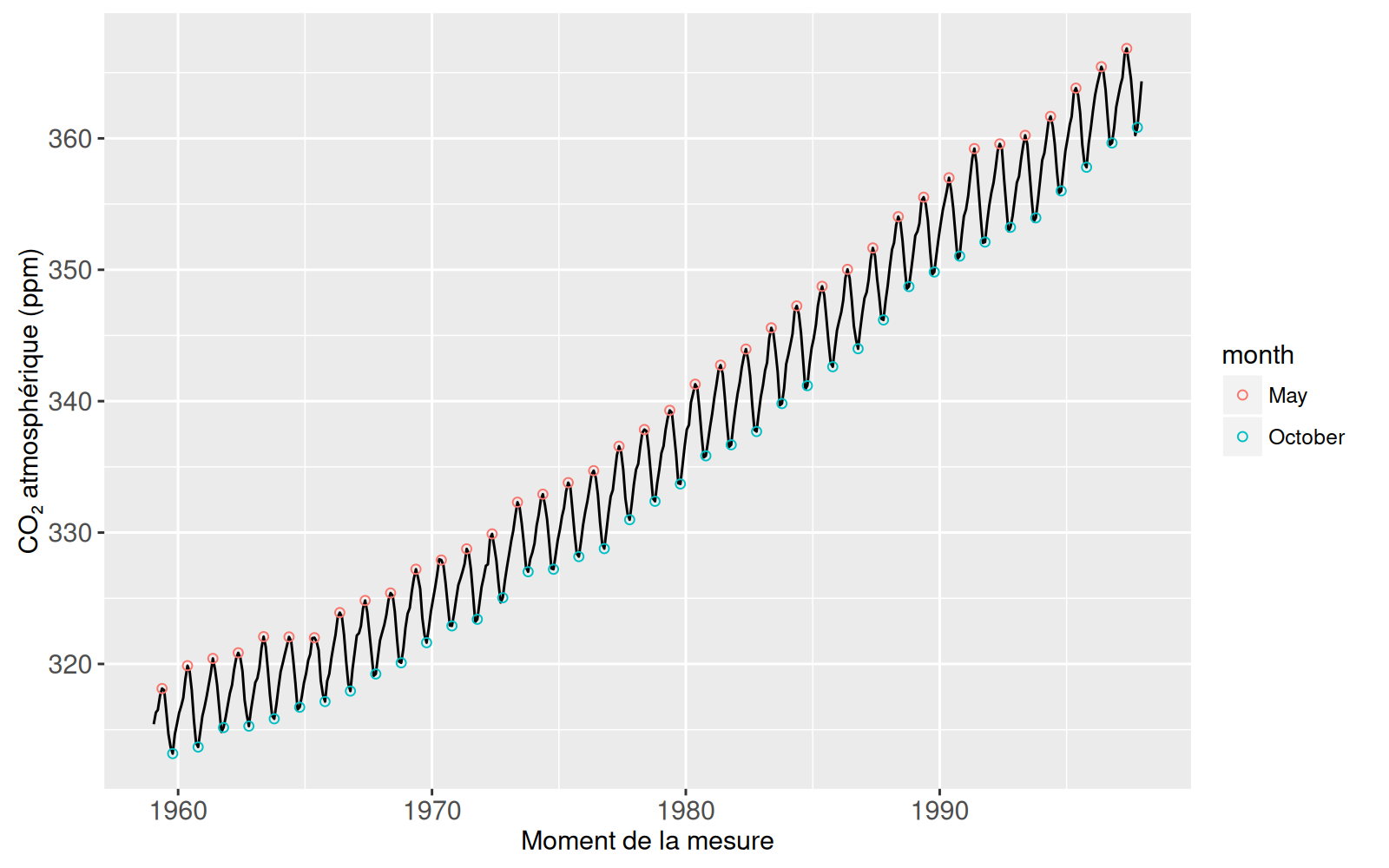
La visualisation des données statiques montre que les concentrations de CO₂ ont augmenté au cours de la seconde moitié du XXᵉ siècle. Cette visualisation des données porte le nom de courbe de Keeling, du nom de Charles David Keeling, le premier scientifique à effectuer des relevés continus et systématiques des taux de CO₂ atmosphérique (Keeling 1960). La tendance générale à l’augmentation peut être expliquée par le processus chimique de la combustion, qui transforme l’oxygène en CO₂. Keeling a noté que « le taux d’augmentation observé est proche de celui que l’on peut attendre de la combustion de combustibles fossiles » (Keeling 1960).
La visualisation des données révèle également une intéressante tendance saisonnière qui, chaque année, atteint son maximum en mai et son minimum en octobre. Cette tendance saisonnière s’explique par l’activité des forêts de l’hémisphère Nord. Les feuilles des arbres réalisent la photosynthèse, un processus chimique qui convertit le CO₂ en oxygène. Or, dans l’hémisphère Nord, les arbres n’ont pas de feuilles en hiver et le CO₂ s’accumule dans l’atmosphère jusqu’à atteindre son maximum en mai. La photosynthèse reprend lorsque le feuillage réapparaît au printemps et se poursuit tout au long de l’été, faisant baisser la concentration de CO₂ dans l’atmosphère jusqu’à son minimum annuel en octobre.
Nous disons que cette visualisation des données est « statique » ou « non interactive » parce que le lecteur peut la visualiser, mais ne peut pas modifier ce qui est affiché. Ce genre de visualisation convient parfaitement aux ensembles de données de taille moyenne, dans lesquels nous pouvons voir tous les détails de l’ensemble de données. Cependant, comme nous le verrons dans la section suivante, la visualisation statique n’est pas suffisante pour montrer tous les détails des grands ensembles de données.
1.3.4 Analyse de données volumineuses avec visualisation des données interactive
Certains ensembles de données sont si volumineux qu’il n’est ni possible ni souhaitable de tracer toutes les données à la fois dans une visualisation statique. Pour de tels ensembles, les approches traditionnelles d’analyse consistent à résumer les données, puis à visualiser ce résumé. Cependant, le résumé graphique peut être trompeur, car il ne révèle pas tous les détails des données originales. Dans de telles situations, la visualisation des données interactive devient utile.
Examinons tout d’abord une forme légèrement plus élaborée de la courbe de Keeling.
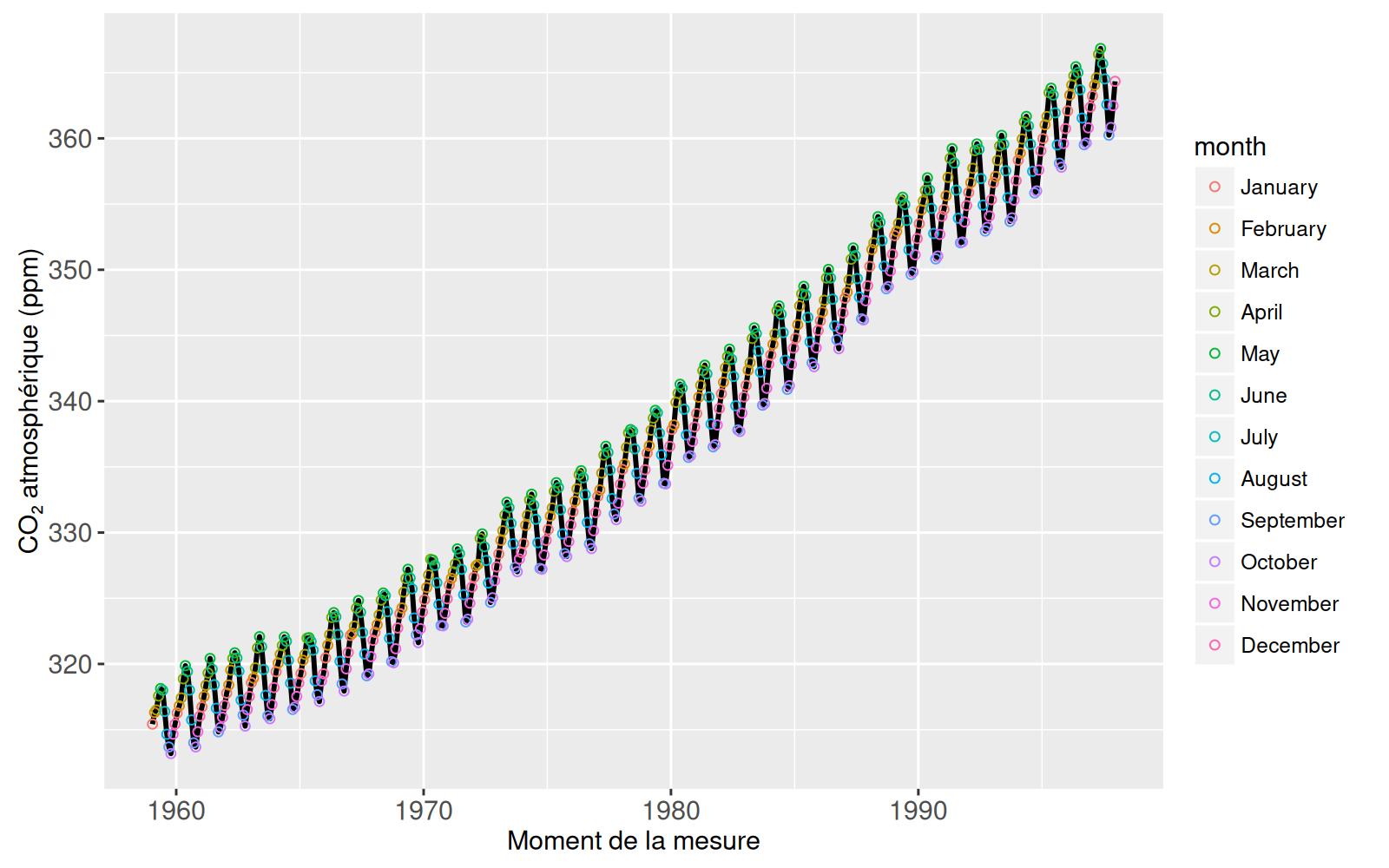
Le graphique ci-dessus présente des points colorés pour chaque mois de l’année, plutôt qu’uniquement pour mai et octobre, les pics que nous voulions mettre en évidence. Ce graphique statique est moins instructif que le précédent, car il ne fait pas ressortir les extrêmes. Il s’agit d’un exemple où il n’est pas souhaitable de tracer toutes les données simultanément. Nous pouvons résoudre ce problème en utilisant le graphique interactif suivant :
Dans le graphique ci-dessus, les mois de mai et octobre sont mis en évidence par défaut, mais l’utilisateur peut cliquer sur la légende pour mettre à jour l’accentuation. Cet exemple simple illustre l’idée principale de la visualisation interactive des données à l’aide de animint(). De nombreux choix doivent être effectués pour montrer les détails des ensembles de données volumineux. Par exemple, le choix des mois à mettre en valeur dans le graphique ci-dessus. Plutôt que de fixer de tels choix dans un graphique statique, l’objectif de la visualisation des données interactive est de permettre au lecteur de voir à quoi ressemble le graphique avec des choix différents. Dans l’exemple ci-dessus, nous avons utilisé une légende interactive qui permet à l’utilisateur de sélectionner différents mois et de voir les effets sur le graphique.
L’exemple ci-dessus illustre bien comment clickSelects et showSelected, les deux mots-clés introduits par animint2 permettent l’interaction. Sans entrer dans les détails, le graphique ci-dessus utilise clickSelects=mois pour la légende interactive, ce qui signifie qu’un clic sur la légende modifiera les mois sélectionnés. En outre, nous avons utilisé showSelected=mois pour les points, de sorte que seuls les points correspondant aux mois sélectionnés par l’utilisateur sont affichés. Dans les chapitres 3 et 4, nous expliquerons comment concevoir des visualisations de données en utilisant ces deux nouveaux mots-clés dans l’écriture du code R.
1.4 Résumé du chapitre et exercices
Ce chapitre a introduit quelques notions de base sur les données et a proposé des définitions des différentes tailles d’ensembles de données : petite, moyenne et grande.
- D’après les définitions des tailles des jeux de données présentées dans ce chapitre, quelle est la différence entre petite et moyenne ?
- Quelle est la différence entre moyenne et grande ?
Au chapitre 2, nous vous présentons la grammaire des graphiques pour la création des visualisations des données.