# Détection supervisée des ruptures
<!-- paragraph -->
```{r setup, echo=FALSE}
knitr::opts_chunk$set(fig.path="ch16-figures/")
```
<!-- paragraph -->
Dans ce chapitre, nous explorerons plusieurs visualisations de modèles de détection supervisée des ruptures dans des données séquentielles.
<!-- paragraph -->
Plan du chapitre :
<!-- paragraph -->
- Nous commençons par quelques visualisations statiques du jeu de données `intreg`.
<!-- comment -->
- Nous créons ensuite une visualisation interactive. Un clic dans un graphique permettra de sélectionner le nombre de ruptures et de segments, et un autre graphique affichera le modèle correspondant.
<!-- comment -->
- Nous terminons avec une visualisation statique du modèle de régression linéaire de la marge maximale, puis nous suggérons des exercices pour créer une version interactive.
<!-- paragraph -->
## Figures statiques {#static-change-point}
<!-- paragraph -->
Nous commençons par charger le jeu de données `intreg`.
<!-- paragraph -->
```{r intreg}
library(animint2)
data(intreg)
library(data.table)
lapply(intreg, function(df)data.table(df)[1:2])
```
<!-- paragraph -->
On constate ci-dessus qu’il s’agit d’une liste nommée de sept `data.frames` apparentés.
<!-- comment -->
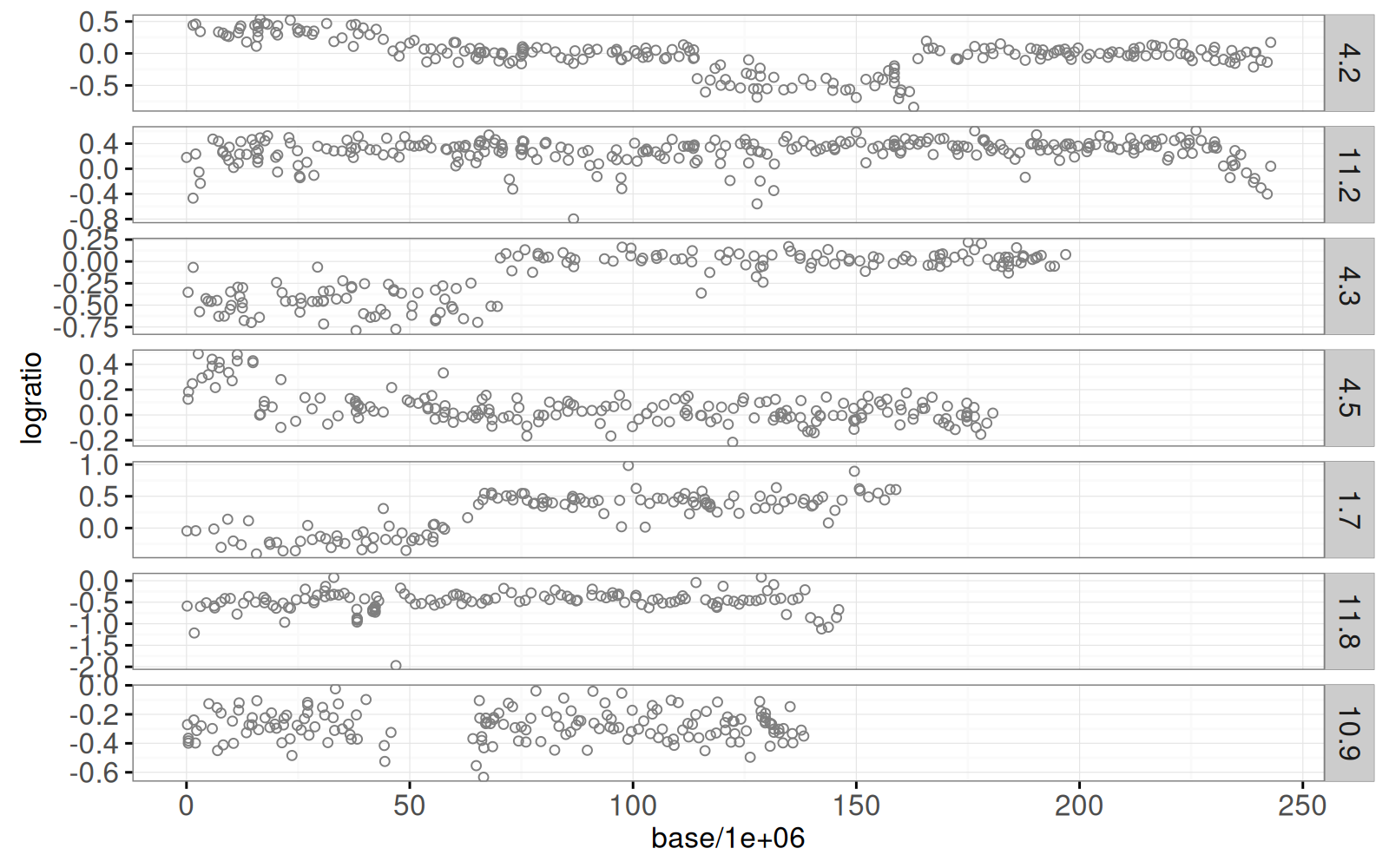
Nous explorons d’abord ces données en traçant les signaux dans des facettes séparées.
<!-- paragraph -->
```{r signals}
data.color <- "grey50"
gg.signals <- ggplot()+
theme_bw()+
facet_grid(signal ~ ., scales="free")+
geom_point(aes(
base/1e6, logratio,
showSelected="signal"),
color=data.color,
data=intreg$signals)
gg.signals
```
<!-- paragraph -->
Chaque point tracé ci-dessus représente une mesure approximative du nombre de copies d’ADN (logratio) en fonction de la position des bases sur un chromosome.
<!-- comment -->
Ces données proviennent d’analyses à haut débit essentielles pour diagnostiquer certains cancers, comme le neuroblastome.
<!-- paragraph -->
Une partie importante du diagnostic consiste à détecter les points de rupture, soit les changements abrupts au sein d’un chromosome donné (panneau).
<!-- comment -->
Le graphique ci-dessus en montre plusieurs.
<!-- comment -->
En particulier, le signal 4.3 semble en avoir un et le signal 4.2 trois.
<!-- comment -->
Ces données sont fournies par des médecins de l’Institut Curie (Paris, France) qui ont annoté visuellement les régions avec et sans points de rupture.
<!-- comment -->
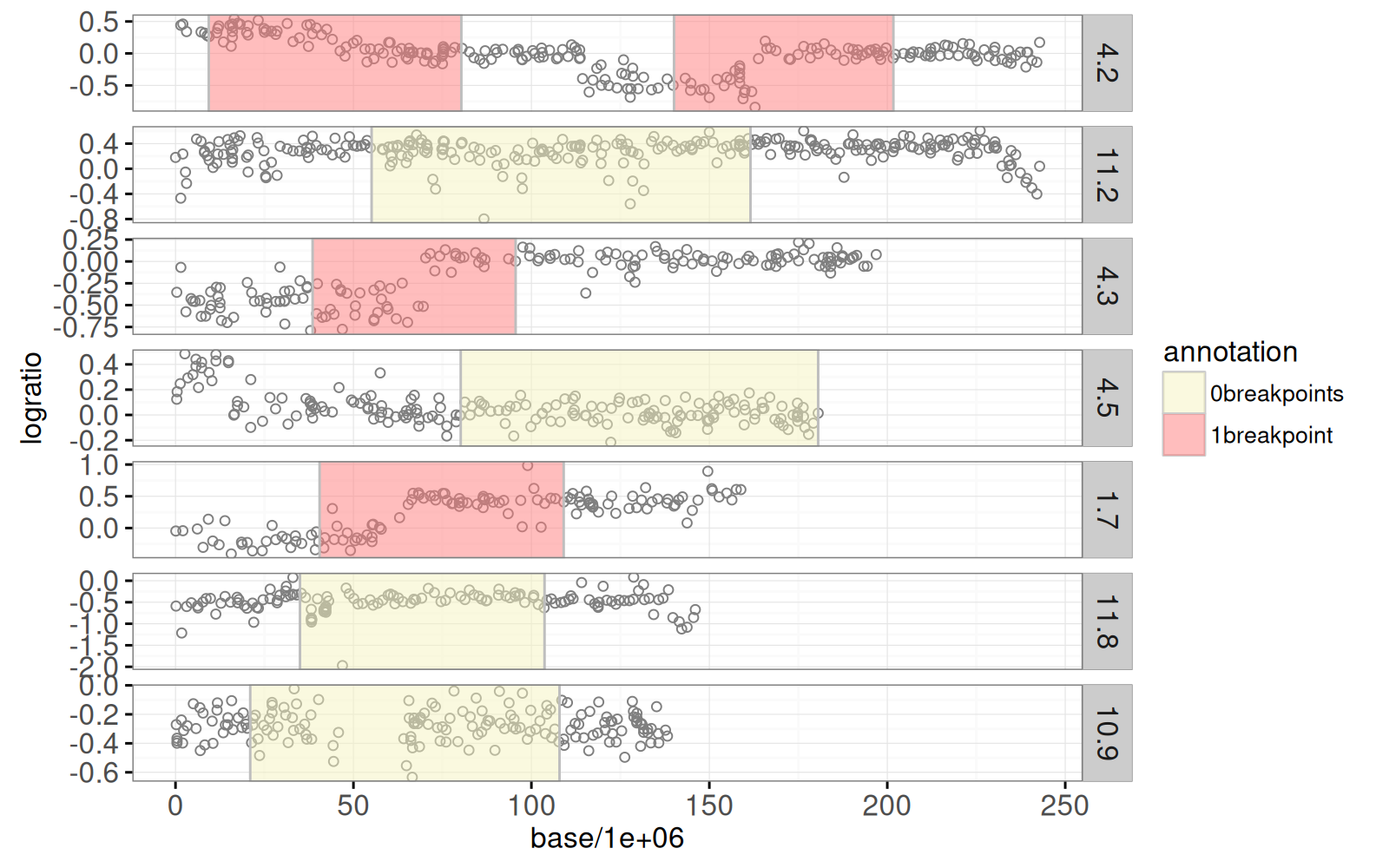
Elles sont disponibles en tant que `intreg$annotations` et sont tracées ci-dessous :
<!-- paragraph -->
```{r annotations}
breakpoint.colors <- c(
"1breakpoint"="#ff7d7d",
"0breakpoints"='#f6f4bf')
gg.ann <- gg.signals+
scale_fill_manual(values=breakpoint.colors)+
geom_tallrect(aes(
xmin=first.base/1e6, xmax=last.base/1e6,
fill=annotation),
color="grey",
alpha=0.5,
data=intreg$annotations)
gg.ann
```
<!-- paragraph -->
Le graphique ci-dessus montre en jaune les régions sans points de rupture significatifs, et en rouge celles où ils sont présents.
<!-- comment -->
L’objectif de l’analyse de ces données est d’apprendre à partir des données étiquetées limitées (régions colorées) et de fournir des prédictions cohérentes sur les points de rupture (même dans les régions non étiquetées).
<!-- paragraph -->
Afin de détecter ces points de rupture, nous avons ajusté des modèles de segmentation de vraisemblance maximale en utilisant l’algorithme efficace implémenté dans `jointseg::Fpsn`.
<!-- comment -->
Les moyennes des segments sont disponibles dans `intreg$segments` et les points de rupture prédits sont disponibles dans `intreg$breaks`.
<!-- comment -->
Pour chaque signal, on dispose d’une séquence de modèles de 1 à 20 segments.
<!-- comment -->
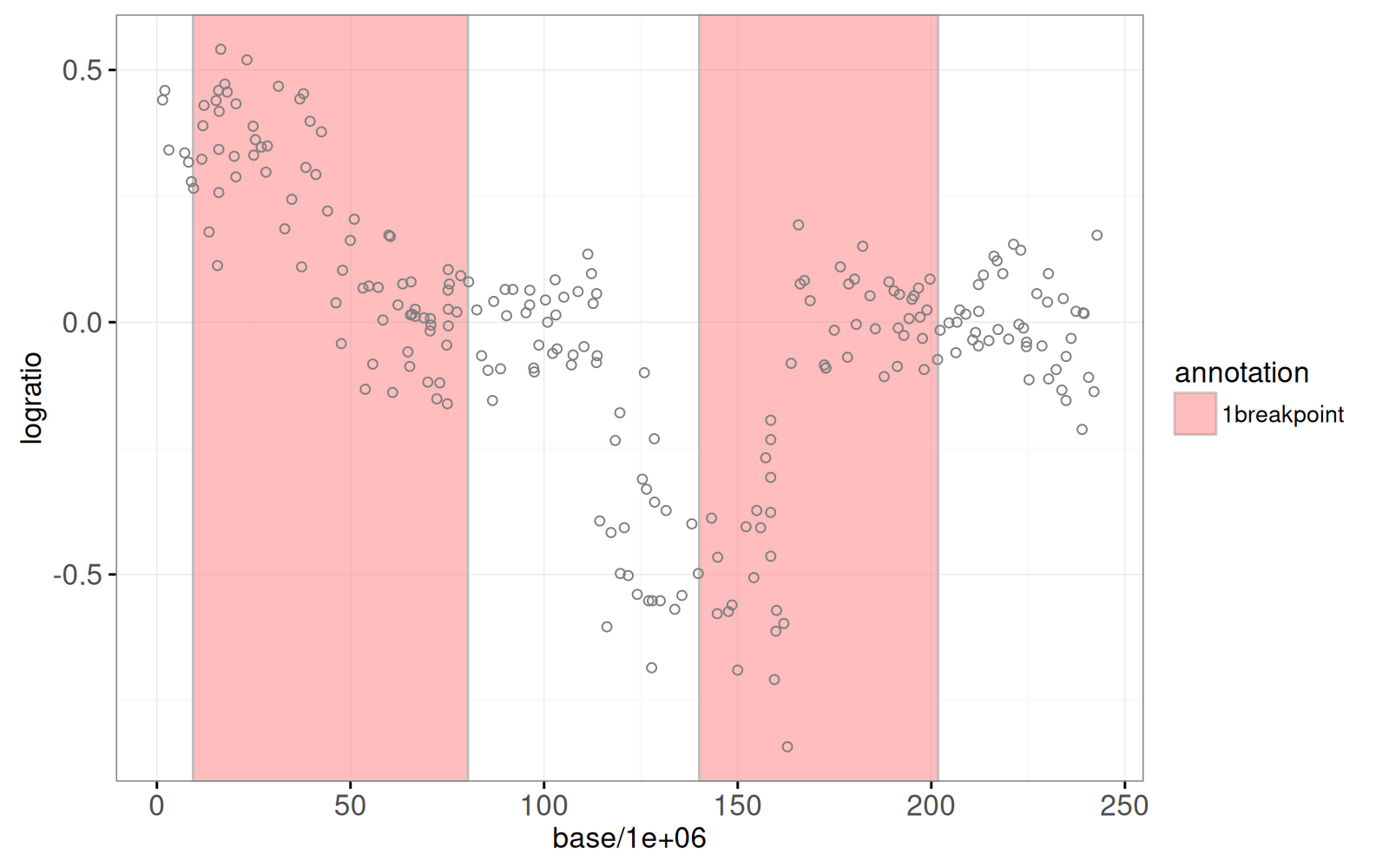
Concentrons-nous d’abord sur un signal :
<!-- paragraph -->
```{r one}
sig.name <- "4.2"
show.segs <- 7
sig.labels <- subset(intreg$annotations, signal==sig.name)
gg.one <- ggplot()+
theme_bw()+
theme(panel.margin=grid::unit(0, "lines"))+
geom_tallrect(aes(
xmin=first.base/1e6, xmax=last.base/1e6,
fill=annotation),
color="grey",
alpha=0.5,
data=sig.labels)+
geom_point(aes(
base/1e6, logratio),
color=data.color,
data=subset(intreg$signals, signal==sig.name))+
scale_fill_manual(values=breakpoint.colors)
gg.one
```
<!-- paragraph -->
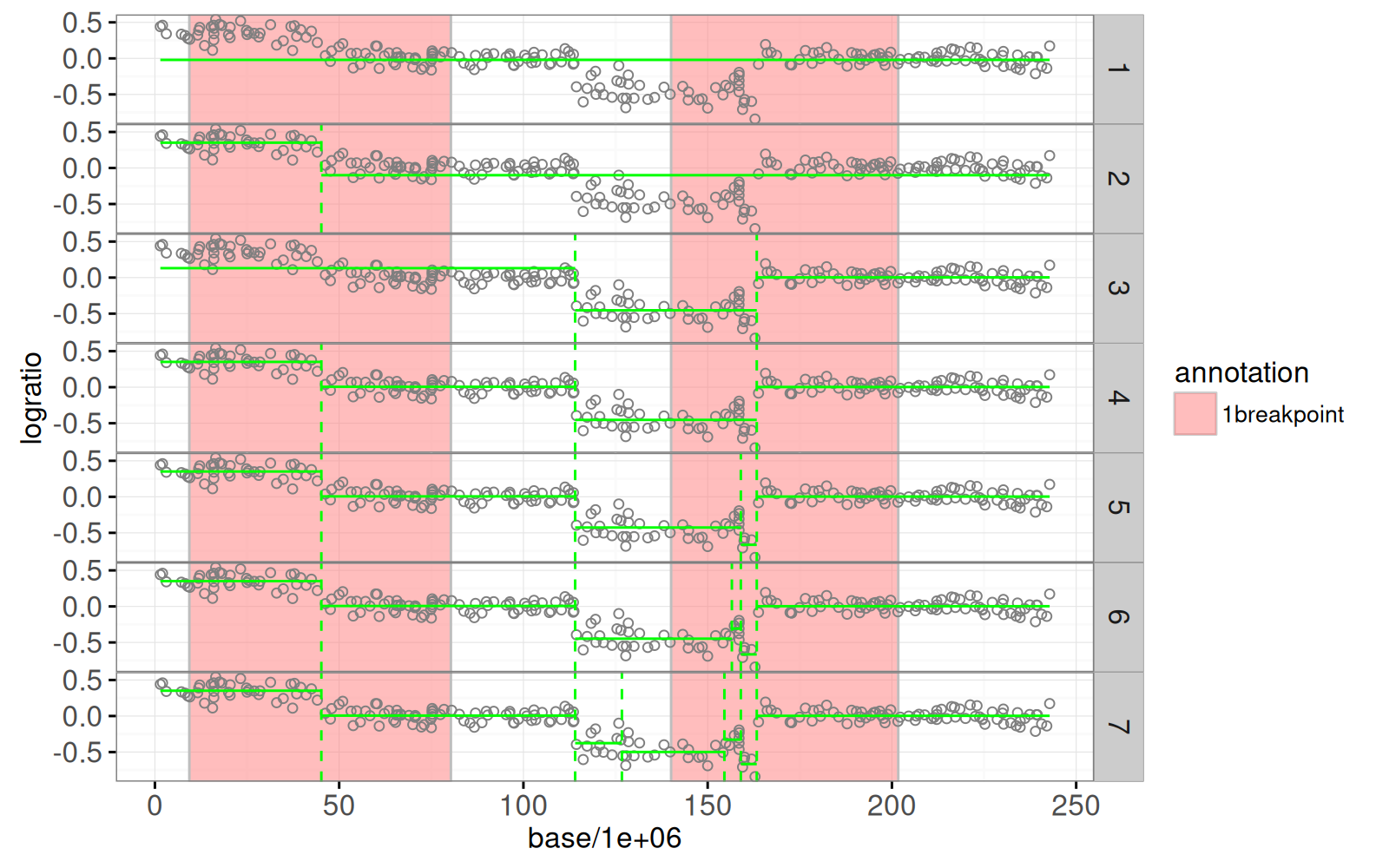
Nous traçons ci-dessous certains de ces modèles pour l’un des signaux :
<!-- paragraph -->
```{r models}
sig.segs <- data.table(
intreg$segments)[signal == sig.name & segments <= show.segs]
sig.breaks <- data.table(
intreg$breaks)[signal == sig.name & segments <= show.segs]
model.color <- "green"
gg.models <- gg.one+
facet_grid(segments ~ .)+
geom_segment(aes(
first.base/1e6, mean,
xend=last.base/1e6, yend=mean),
color=model.color,
data=sig.segs)+
geom_vline(aes(
xintercept=base/1e6),
color=model.color,
linetype="dashed",
data=sig.breaks)
gg.models
```
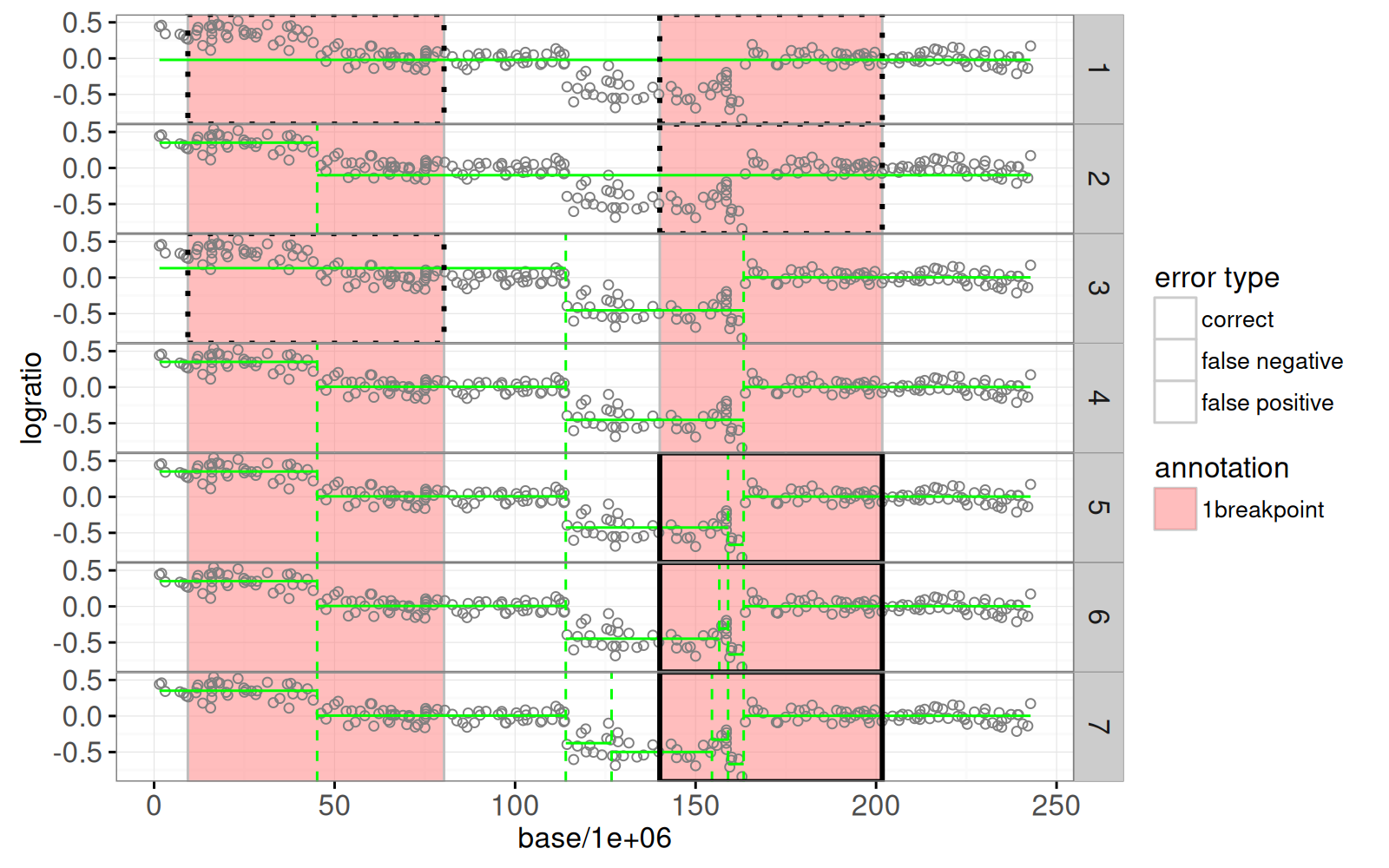
<!-- paragraph -->
Le graphique ci-dessus montre les modèles de segmentation de vraisemblance maximale en vert (de un à six segments).
<!-- comment -->
Ci-dessous, nous utilisons la fonction `penaltyLearning::labelError` pour calculer l’erreur d’étiquette, qui établit quels modèles correspondent à quelles étiquettes :
<!-- paragraph -->
```{r labelerr}
sig.models <- data.table(segments=1:show.segs, signal=sig.name)
sig.errors <- penaltyLearning::labelError(
sig.models, sig.labels, sig.breaks,
change.var="base",
label.vars=c("first.base", "last.base"),
model.vars="segments",
problem.vars="signal")
```
<!-- paragraph -->
Le `data.table` (tableau de données) `sig.errors$label.errors` contient une ligne pour chaque combinaison (modèle, étiquette).
<!-- comment -->
La colonne `status` indique le type d’erreur d’étiquette : `false negative` pour trop peu de ruptures, `false positive` pour un trop grand nombre ou `correct` pour le bon nombre.
<!-- paragraph -->
```{r plotlabelerr}
gg.models+
geom_tallrect(aes(
xmin=first.base/1e6, xmax=last.base/1e6,
linetype=status),
data=sig.errors$label.errors,
color="black",
size=1,
fill=NA)+
scale_linetype_manual(
"type d'erreur",
values=c(
correct=0,
"false negative"=3,
"false positive"=1))
```
<!-- paragraph -->
En examinant le graphique des erreurs d’étiquettes ci-dessus, il devient évident que le modèle à quatre segments devrait être sélectionné, car il permet d’obtenir un nombre nul d’erreurs d’étiquette.
<!-- comment -->
Un certain nombre de méthodes peuvent être utilisées pour sélectionner le meilleur modèle.
<!-- comment -->
L’une d’elles consiste à sélectionner le modèle avec $s$ segments, selon la formule $S^*(\lambda)=L_s + \lambda*s$, où $L_s$ est la perte totale du modèle avec $s$ segments, et $\lambda$ est une pénalité non négative.
<!-- comment -->
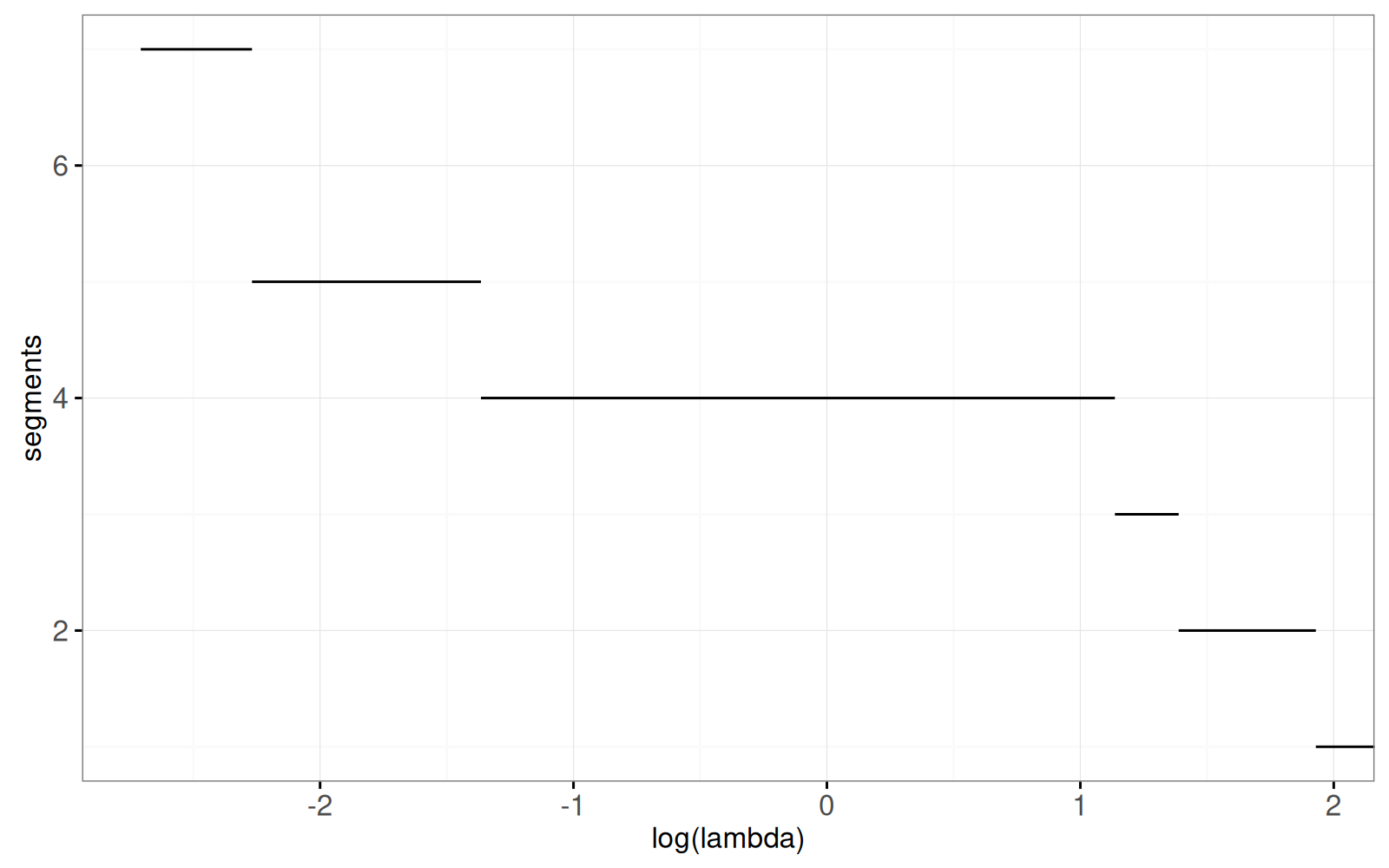
Le graphique ci-dessous montre la fonction de sélection du modèle $S^*(\lambda)$ pour ce jeu de données :
<!-- paragraph -->
```{r selection}
sig.selection <- data.table(
intreg$selection)[signal == sig.name & segments <= show.segs]
gg.selection <- ggplot()+
theme_bw()+
geom_segment(aes(
min.L, segments,
xend=max.L, yend=segments),
data=sig.selection)+
xlab("log(lambda)")
gg.selection
```
<!-- paragraph -->
Le graphique ci-dessus montre clairement que la fonction de sélection du modèle est décroissante.
<!-- comment -->
Dans la prochaine section, nous réalisons une version interactive de ces deux graphiques dans laquelle on peut cliquer sur le graphique pour sélectionner un modèle.
<!-- paragraph -->
## Figures interactives pour un signal {#interactive-one}
<!-- paragraph -->
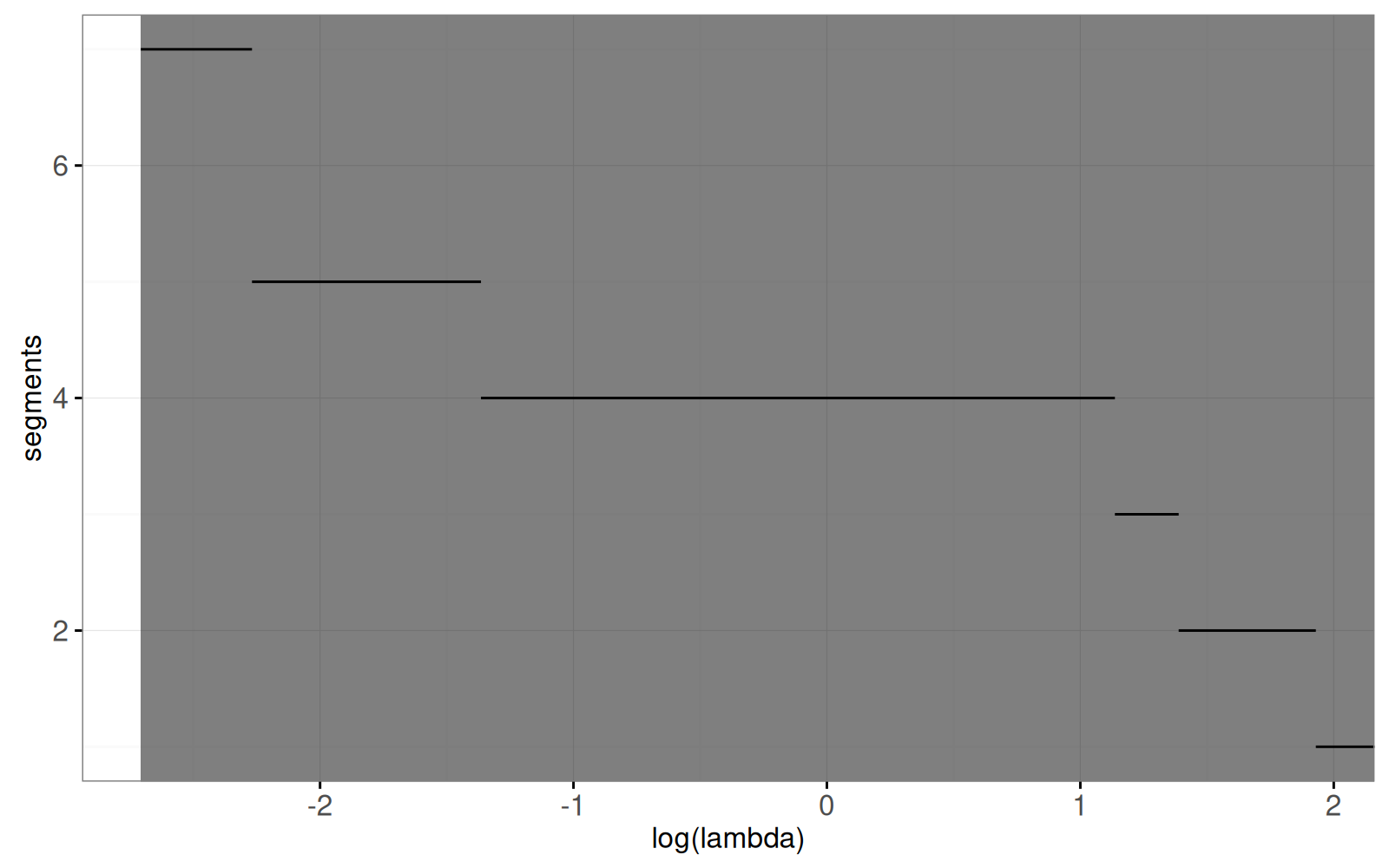
Nous allons créer une figure interactive pour un signal en ajoutant un `geom_tallrect()` avec `clickSelects=segments` au graphique ci-dessus.
<!-- paragraph -->
```{r selectionClick}
interactive.selection <- gg.selection+
geom_tallrect(aes(
xmin=min.L, xmax=max.L),
clickSelects="segments",
data=sig.selection,
color=NA,
fill="black",
alpha=0.5)
interactive.selection
```
<!-- paragraph -->
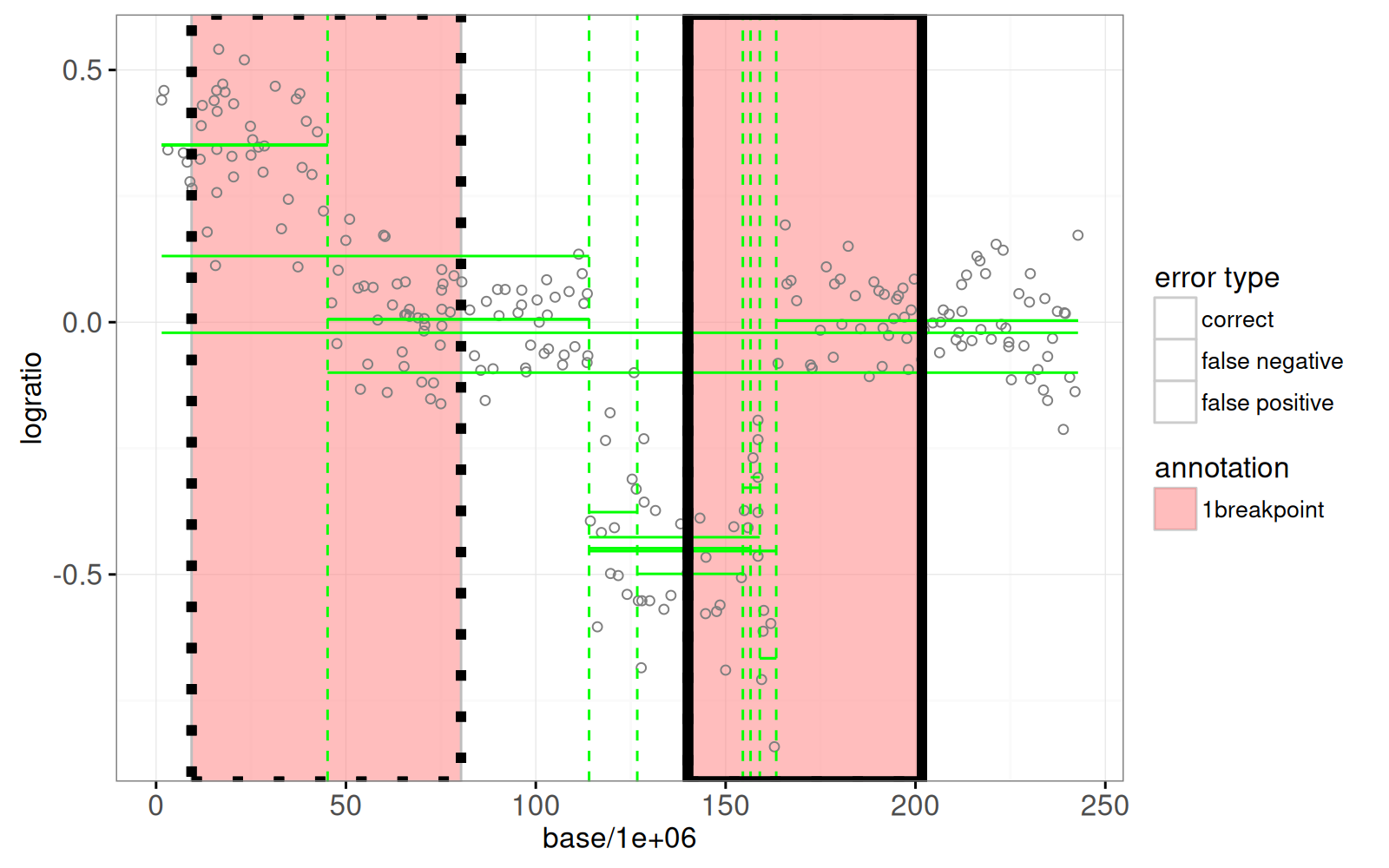
Nous combinons le graphique avec la version non facettée du graphique données/modèles ci-dessous, auquel nous ajoutons `showSelected=segments` aux geoms des modèles :
<!-- paragraph -->
```{r selectionData}
interactive.models <- gg.one+
geom_segment(aes(
first.base/1e6, mean,
xend=last.base/1e6, yend=mean),
showSelected="segments",
color=model.color,
data=sig.segs)+
geom_vline(aes(
xintercept=base/1e6),
showSelected="segments",
color=model.color,
linetype="dashed",
data=sig.breaks)+
geom_tallrect(aes(
xmin=first.base/1e6, xmax=last.base/1e6,
linetype=status),
showSelected="segments",
data=sig.errors$label.errors,
size=2,
color="black",
fill=NA)+
scale_linetype_manual(
"type d'erreur",
values=c(
correct=0,
"false negative"=3,
"false positive"=1))
interactive.models
```
<!-- paragraph -->
Bien entendu, le graphique ci-dessus est peu informatif, car il n’est pas interactif.
<!-- comment -->
Ci-dessous, nous combinons les deux ggplots interactifs dans un `animint` :
<!-- paragraph -->
```{r interactiveOne}
animint(
models=interactive.models+
ggtitle("Modèle sélectionné"),
selection=interactive.selection+
ggtitle("Cliquer pour choisir le nombre de segments"))
```
<!-- paragraph -->
Notez que dans la visualisation ci-dessus, le modèle à six segments ne peut être sélectionné avec une valeur de lambda. Il est donc impossible de sélectionner ce modèle en cliquant sur le graphique.
<!-- comment -->
Cependant, il est possible de le sélectionner en utilisant le menu de sélection des segments (cliquez sur « Show selection menus » au bas de la visualisation des données).
<!-- paragraph -->
## Graphique de régression de la marge maximale statique {#max-margin}
<!-- paragraph -->
Une autre partie de ce jeu de données est `intreg$intervals` qui comporte une ligne par signal.
<!-- comment -->
Les colonnes `min.L` et `max.L` indiquent les valeurs min/max de l’intervalle cible, soit la plage la plus large de valeurs de log(pénalité) avec des erreurs d’étiquette minimales.
<!-- comment -->
Nous traçons ci-dessous cet intervalle en fonction du logarithme du nombre de données dans la séquence :
<!-- paragraph -->
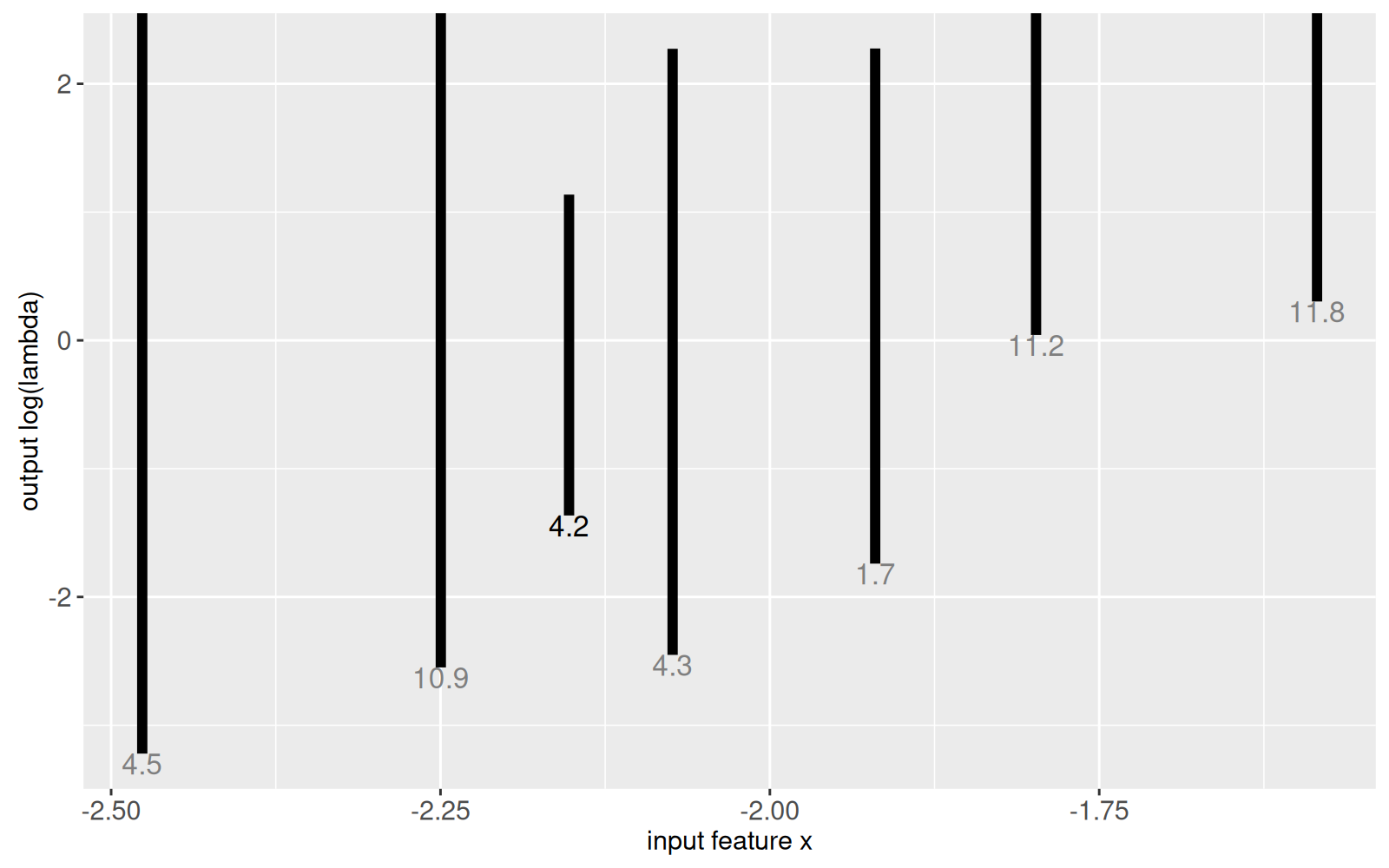
```{r intervals}
gg.intervals <- ggplot()+
geom_segment(aes(
feature, min.L,
xend=feature, yend=max.L),
size=2,
data=intreg$intervals)+
geom_text(aes(
feature, min.L, label=signal,
color=ifelse(signal==sig.name, "black", "grey50")),
vjust=1,
data=intreg$intervals)+
scale_color_identity()+
ylab("sortie de log(lambda)")+
xlab("variable d’entrée x")
gg.intervals
```
<!-- paragraph -->
Les intervalles cibles dans le graphique ci-dessus indiquent la région de l’espace log(lambda) qui sélectionnera un modèle avec des erreurs d’étiquette minimales.
<!-- comment -->
Il y a un intervalle par signal ; nous avons créé un `animint` dans la section précédente pour le signal indiqué en noir.
<!-- comment -->
Des algorithmes d’apprentissage automatique peuvent être utilisés pour trouver une fonction de pénalité qui coupe chacun des intervalles et maximise la marge (distance entre la fonction de régression et la limite de l’intervalle le plus proche).
<!-- comment -->
Les données pour la fonction de régression linéaire de la marge maximale se trouvent dans `intreg$model` et sont représentés dans le graphique ci-dessous :
<!-- paragraph -->
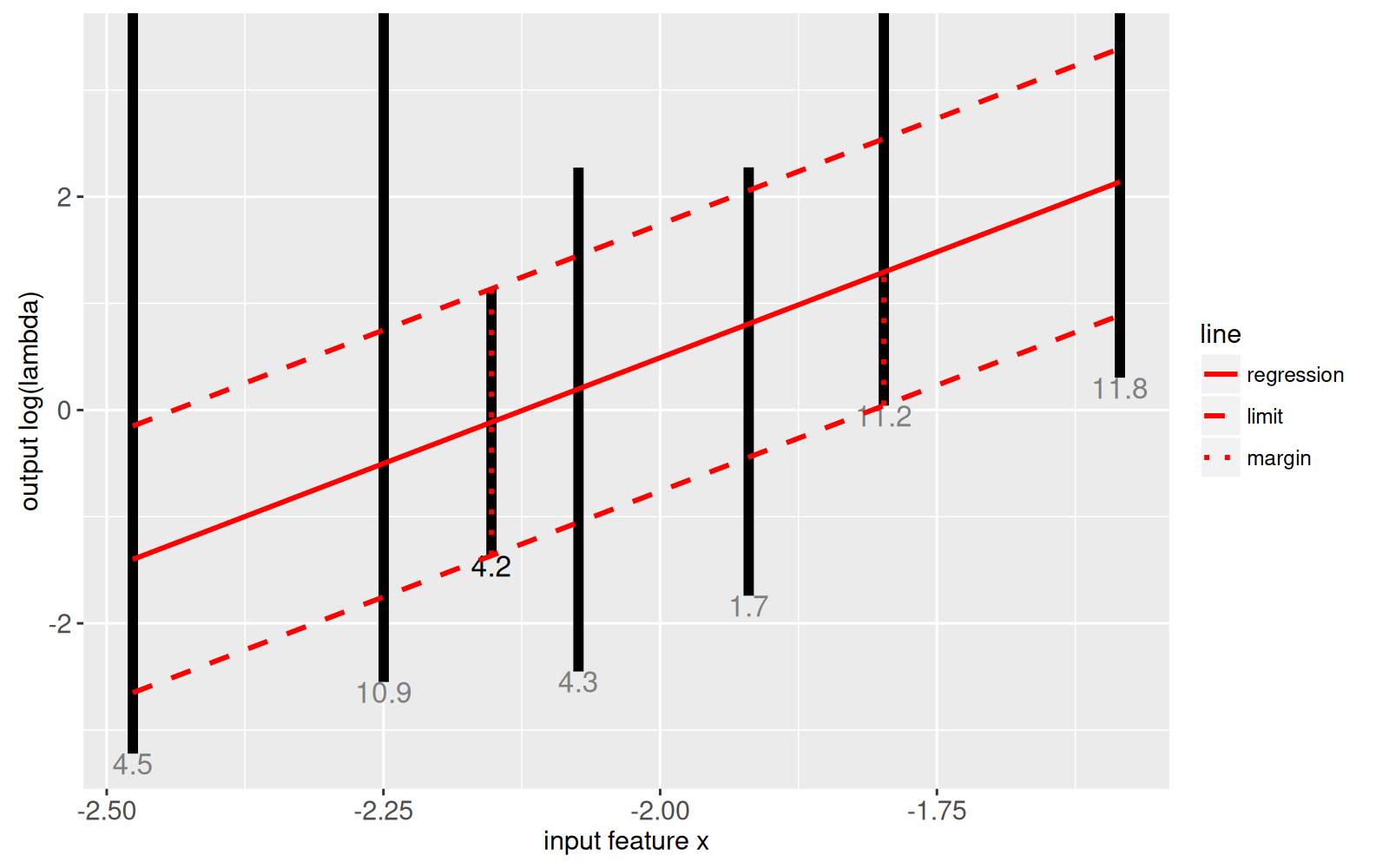
```{r maxMargin}
gg.mm <- gg.intervals+
geom_segment(aes(
min.feature, min.L,
xend=max.feature, yend=max.L,
linetype=line),
color="red",
size=1,
data=intreg$model)+
scale_linetype_manual(
values=c(
regression="solid",
margin="dotted",
limit="dashed"))
gg.mm
```
<!-- paragraph -->
Le graphique ci-dessus représente la fonction de régression linéaire de la marge maximale f(x) par une ligne rouge pleine.
<!-- comment -->
On voit clairement qu’elle coupe chaque intervalle cible en noir et maximise la marge (lignes pointillées verticales rouges).
<!-- comment -->
Pour plus d’informations sur la détection supervisée des points de rupture, voir le tutoriel du useR 2017 [@my_useR_2017_tutorial].
<!-- paragraph -->
Vous savez maintenant comment visualiser les sept parties du jeu de données `intreg`. Le reste du chapitre est consacré à des exercices.
<!-- paragraph -->
## Résumé du chapitre et exercices {#ch16-exercises}
<!-- paragraph -->
Exercices :
<!-- paragraph -->
- Ajoutez un `geom_text()` qui affiche le nom du signal sélectionné en haut du graphique, en `interactive.models` dans le premier `animint` ci-dessus.
<!-- comment -->
- Créez une animation avec deux graphiques qui montre l’ensemble de données correspondant à chaque intervalle sur le graphique de régression de la marge maximale.
<!-- comment -->
L’un des graphiques doit montrer une version interactive du graphique de régression de la marge maximale cliquable pour la sélection d’un signal.
<!-- comment -->
L’autre doit afficher le jeu de données pour le signal sélectionné.
<!-- comment -->
- Dans le `animint` créé dans l’exercice précédent, ajoutez un troisième graphique incluant la fonction de sélection de modèles pour le signal sélectionné.
<!-- comment -->
- Dans la visualisation précédente, supprimez le troisième graphique, et ajoutez une facette avec les mêmes informations au graphique de régression, avec les axes alignés.
<!-- comment -->
Ajoutez une autre facette qui indique le nombre d’étiquettes incorrectes (`intreg$selection$cost`) pour chaque valeur de log(lambda).
<!-- comment -->
- Ajoutez des geoms pour sélectionner le nombre de segments.
<!-- comment -->
Un clic sur le graphique de sélection du modèle doit permettre de sélectionner le nombre de segments, et entraîner la mise à jour du modèle affiché et des erreurs d’étiquette sur le graphique pour le signal sélectionné.
<!-- comment -->
Ajoutez également une indication visuelle du modèle sélectionné sur le graphique de régression de la marge maximale.
<!-- comment -->
Le résultat devrait ressembler à ceci [@mmir_vis].
<!-- comment -->
- Créez une autre visualisation des données à partir du graphique à facettes `gg.signals` présenté au début de ce chapitre.
<!-- comment -->
Ajoutez un graphique permettant de sélectionner le nombre de segments pour chaque signal.
<!-- comment -->
Dans le graphique à facettes, montrez le modèle sélectionné pour chaque signal (il devrait y avoir une variable de sélection distincte pour chaque signal). Vous pouvez utiliser les `clickSelects` et `showSelected` nommés comme expliqué dans le [chapitre 14](/ch14)).
<!-- comment -->
Le résultat devrait ressembler à ceci [@mmir_chipseq].
<!-- paragraph -->
Dans le [chapitre 17](/ch17), nous vous expliquerons comment visualiser l’algorithme d’agrégation des K-moyennes.
<!-- paragraph -->