library(animint2)
data(BanqueMondiale, package="animint2fr")
BanqueMondiale$Region <- sub(
" (all income levels)", "", BanqueMondiale$region, fixed=TRUE)
library(data.table)
not.na <- data.table(BanqueMondiale)[
!(is.na(espérance.de.vie) | is.na(taux.de.fertilité))
]8 Données de la Banque mondiale
Dans ce chapitre, nous explorerons plusieurs visualisations des données de la Banque mondiale.
Plan du chapitre :
- Nous commençons par charger le jeu de données de la Banque mondiale et définir quelques fonctions pour créer un ggplot multipanneaux avec plusieurs geoms.
- Nous créons ensuite un graphique de série temporelle pour l’espérance de vie.
- Nous ajoutons ensuite un nuage de points de l’espérance de vie en fonction du taux de fertilité dans un deuxième panneau.
- Enfin, nous ajoutons un troisième panneau avec une série temporelle pour le taux de fertilité.
8.1 Chargement des données et définition des fonctions
Tout d’abord, nous chargeons l’ensemble des données de la Banque mondiale. Nous ne considérons que le sous-ensemble qui a des valeurs définies à la fois pour espérance.de.vie et pour taux.de.fertilité.
Nous allons également tracer la variable population à l’aide d’une légende de taille. Avant de tracer le graphique, nous nous assurerons qu’aucune valeur n’est manquante.
not.na[is.na(not.na$population)] iso2c country year fertility.rate life.expectancy population
1: KW Kuwait 1992 2.338 72.95266 NA
2: KW Kuwait 1993 2.341 73.07373 NA
3: KW Kuwait 1994 2.413 73.18724 NA
GDP.per.capita.Current.USD 15.to.25.yr.female.literacy iso3c
1: NA NA KWT
2: NA NA KWT
3: NA NA KWT
region capital longitude
1: Middle East & North Africa (all income levels) Kuwait City 47.9824
2: Middle East & North Africa (all income levels) Kuwait City 47.9824
3: Middle East & North Africa (all income levels) Kuwait City 47.9824
latitude income lending Region
1: 29.3721 High income: nonOECD Not classified Middle East & North Africa
2: 29.3721 High income: nonOECD Not classified Middle East & North Africa
3: 29.3721 High income: nonOECD Not classified Middle East & North Africa
région espérance.de.vie taux.de.fertilité année
1: Moyen-Orient et Afrique du Nord 72.95266 2.338 1992
2: Moyen-Orient et Afrique du Nord 73.07373 2.341 1993
3: Moyen-Orient et Afrique du Nord 73.18724 2.413 1994
pays PIB.par.habitant.USD alphabétisation revenu
1: Koweït NA NA Revenu élevé : nonOCDE
2: Koweït NA NA Revenu élevé : nonOCDE
3: Koweït NA NA Revenu élevé : nonOCDELe tableau ci-dessus montre que trois lignes ont des valeurs manquantes pour la variable population, elles se rapportent au Koweït entre 1992 et 1994. Le tableau ci-dessous présente les données des années voisines, de 1991 à 1995 :
not.na[
pays == "Koweït" & 1991 <= année & année <= 1995,
.(pays, année, population)] pays année population
1: Koweït 1991 1999651
2: Koweït 1992 NA
3: Koweït 1993 NA
4: Koweït 1994 NA
5: Koweït 1995 1586123Le tableau ci-dessus montre que la population du Koweït a diminué entre 1991 et 1995, ce qui concorde avec la guerre du Golfe survenue dans cette période. Nous remplissons les valeurs manquantes ci-dessous :
not.na[is.na(population), population := 1700000]
not.na[
pays == "Koweït" & 1991 <= année & année <= 1995,
.(pays, année, population)] pays année population
1: Koweït 1991 1999651
2: Koweït 1992 1700000
3: Koweït 1993 1700000
4: Koweït 1994 1700000
5: Koweït 1995 1586123Nous définissons ensuite la fonction suivante utilisée pour ajouter des colonnes aux ensembles de données afin d’affecter des geoms aux facettes.
FACETS <- function(df, top, side){
data.frame(df,
top=factor(top, c("Taux de fertilité", "Années")),
side=factor(side, c("Années", "Espérance de vie")))
}Le code ci-dessus est un exemple de la méthode rajouter une colonne et facettes. Notez que les niveaux des facteurs détermineront l’ordre des facettes dans l’affichage. Nous définissons ci-dessous trois fonctions, une pour chaque facette :
TS.RIGHT <- function(df)FACETS(
df, "Années", "Espérance de vie")
SCATTER <- function(df)FACETS(
df, "Taux de fertilité", "Espérance de vie")
TS.ABOVE <- function(df)FACETS(
df, "Taux de fertilité", "Années")8.2 Premier graphique de la série temporelle
Tout d’abord, nous définissons un ensemble de données avec une ligne pour chaque année, que nous utiliserons pour sélectionner les années à l’aide d’un geom_tallrect() en arrière-plan.
années <- unique(not.na[, .(année)])Nous définissons le ggplot avec un geom_tallrect() en arrière-plan et un geom_line() pour les séries temporelles.
ts.right <- ggplot()+
geom_tallrect(aes(
xmin=année-1/2, xmax=année+1/2),
clickSelects="année",
data=TS.RIGHT(années), alpha=1/2)+
geom_line(aes(
année, espérance.de.vie, group=pays, colour=Region),
clickSelects="pays",
data=TS.RIGHT(not.na), size=4, alpha=3/5)
ts.right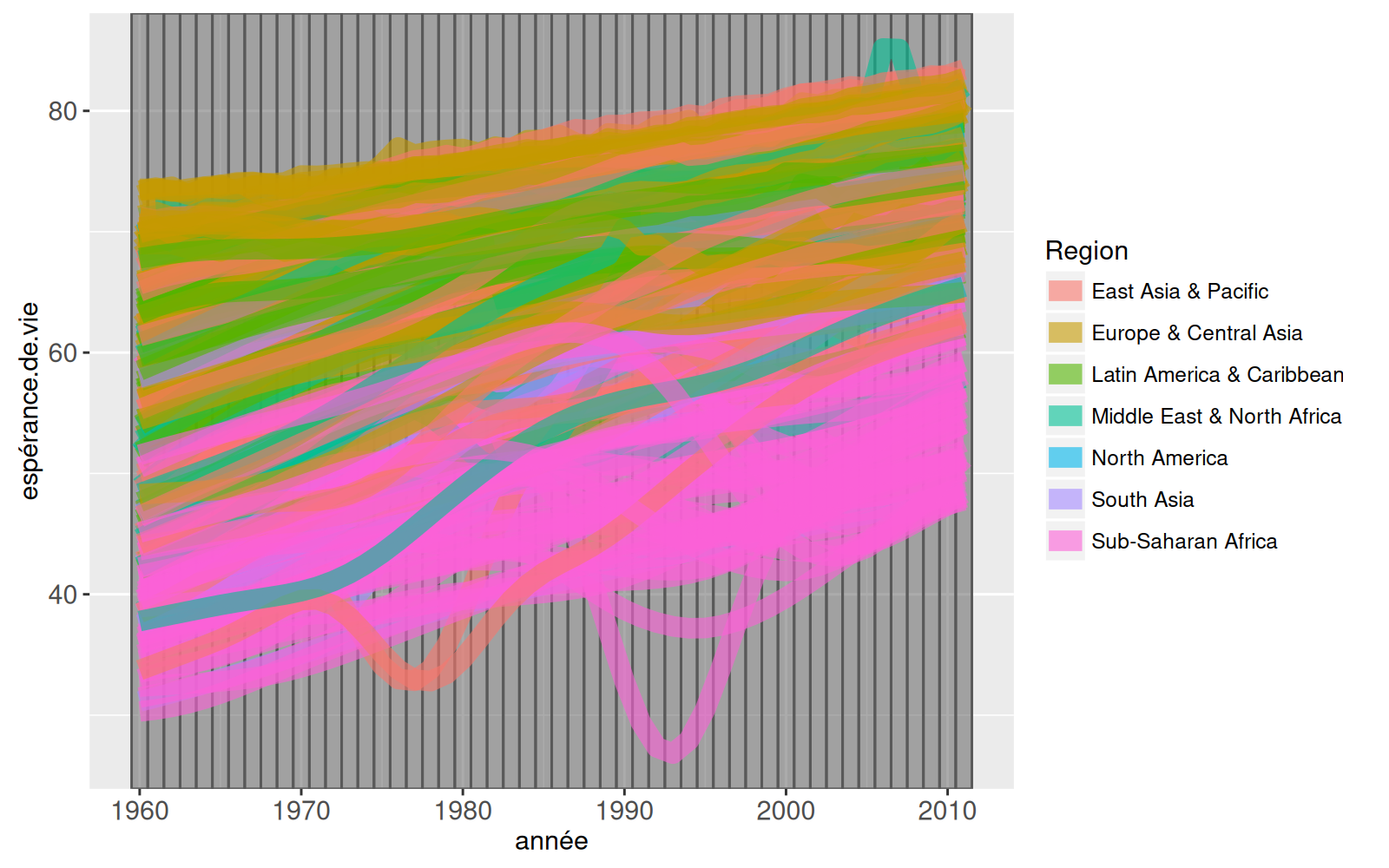
Remarquez que nous avons spécifié clickSelects=année pour qu’un clic sur un tallrect modifie l’année sélectionnée, et clickSelects=pays pour qu’un clic sur une ligne sélectionne ou désélectionne un pays. Notez également que nous avons utilisé TS.RIGHT pour identifier les colonnes que nous utiliserons dans la spécification des facettes (section suivante).
8.3 Ajouter une facette de nuage de points
Nous commençons par simplement ajouter des facettes au graphique de la série temporelle précédente.
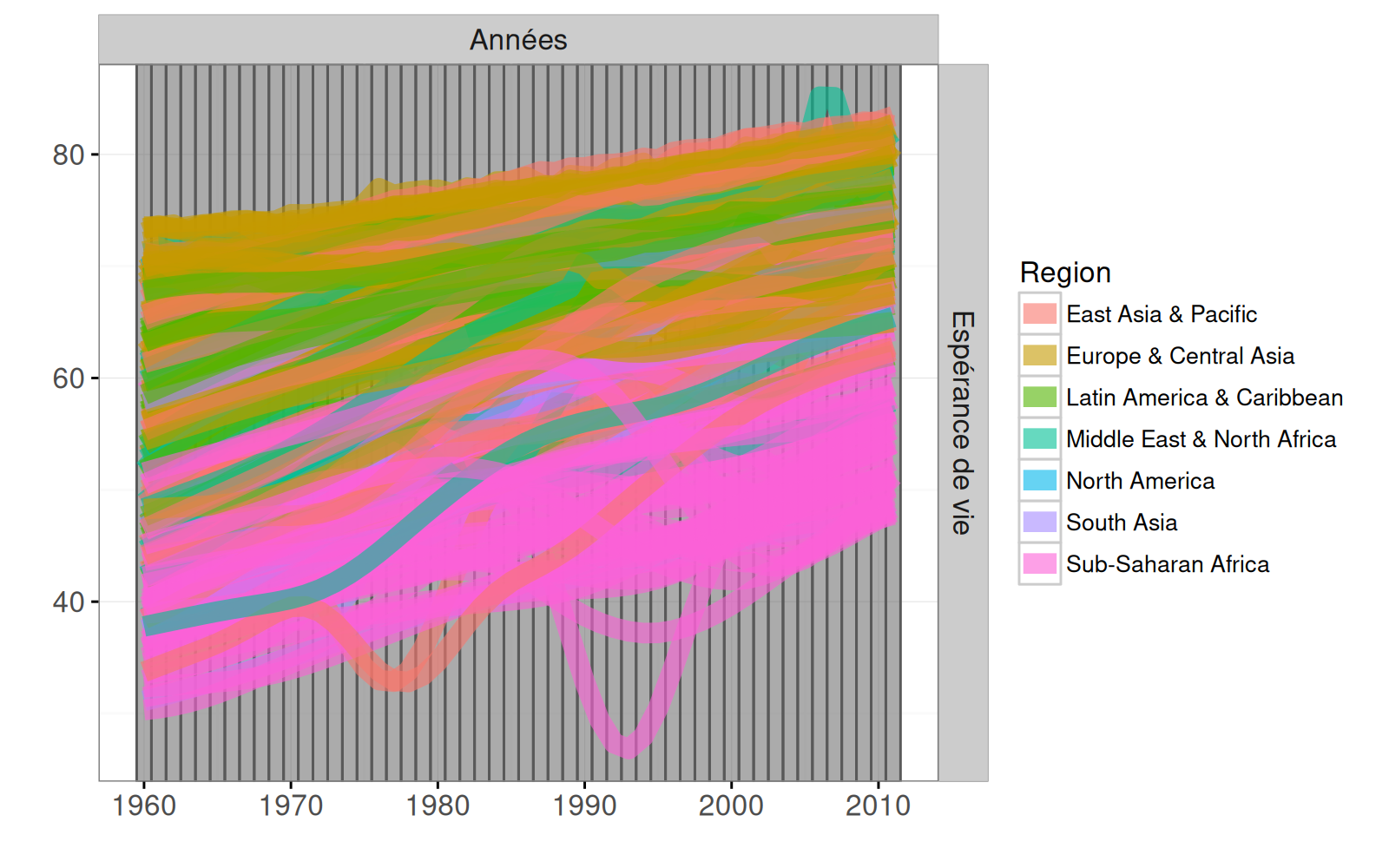
Nous définissons panel.margin=0, une bonne idée pour économiser de l’espace dans un ggplot avec des facettes.
Ci-dessous, nous ajoutons une facette de nuage de points avec un point pour chaque année et chaque pays.
ts.scatter <- ts.facet+
theme_animint(width=600)+
geom_point(aes(
taux.de.fertilité, espérance.de.vie,
colour=Region, size=population,
key=pays), # key aesthetic for animated transitions!
clickSelects="pays",
showSelected="année",
data=SCATTER(not.na))+
scale_size_animint(pixel.range=c(2, 20), breaks=10^(9:5))
ts.scatter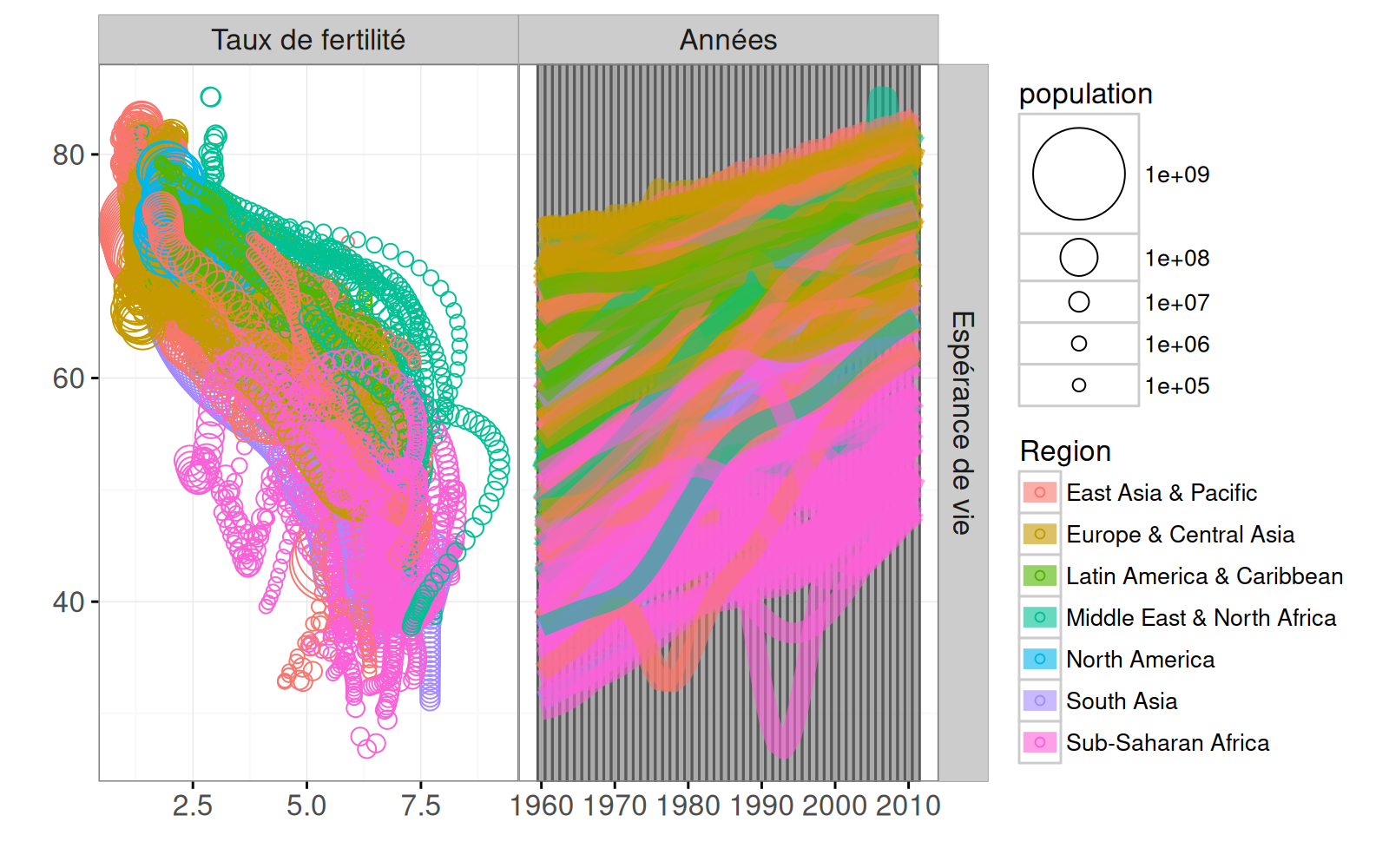
Remarquez comment nous utilisons scale_size_animint pour spécifier l’échelle des tailles en pixels et les intervalles (breaks) dans la légende. Notez également que nous utilisons SCATTER pour spécifier les colonnes top et side utilisées dans la spécification de la facette. Nous affichons également ce ggplot de manière interactive ci-dessous :
animint(ts.scatter)Notez que la sélection unique est utilisée par défaut pour l’année et le pays.
8.4 Ajout d’une facette pour les séries temporelles
Nous ajoutons ci-dessous des rectangles pour sélectionner les années, et des courbes pour afficher le taux de fertilité :
scatter.both <- ts.scatter+
geom_widerect(aes(
ymin=année-1/2, ymax=année+1/2),
clickSelects="année",
data=TS.ABOVE(années), alpha=1/2)+
geom_path(aes(
taux.de.fertilité, année, group=pays, colour=Region),
clickSelects="pays",
data=TS.ABOVE(not.na), size=4, alpha=3/5)
scatter.both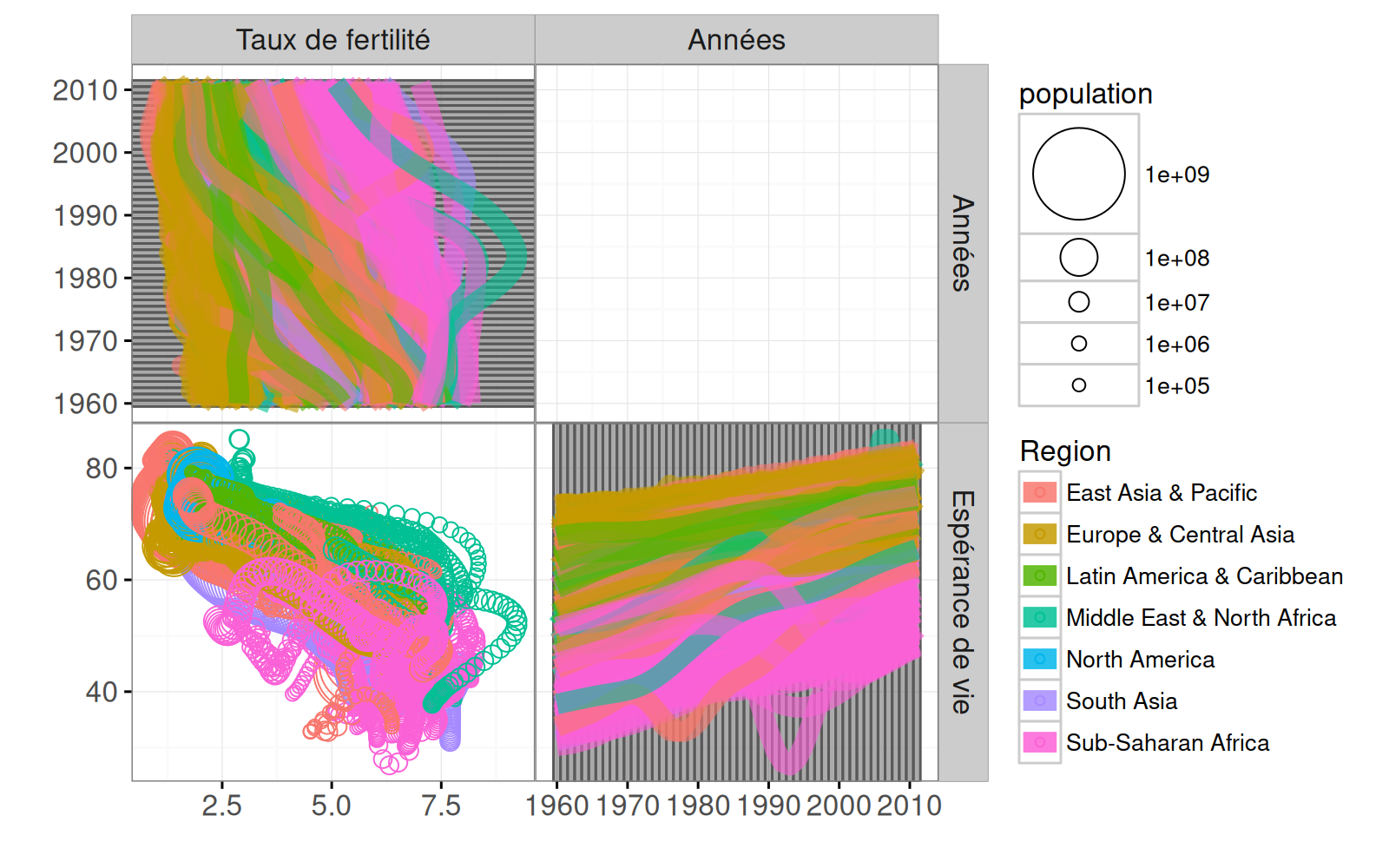
Notez que TS.ABOVE a été utilisé pour spécifier les colonnes des facettes top et side. Nous affichons une version interactive ci-dessous :
vis.scatter.both <- animint(
title="Données de la Banque mondiale (multiple selection, facets)",
scatterBoth=scatter.both+
theme_animint(width=1000, height=800),
duration=list(année=1000),
time=list(variable="année", ms=3000),
first=list(année=1975, pays=c("United States", "Vietnam")),
selector.types=list(pays="multiple"))
vis.scatter.both8.5 Résumé du chapitre et exercices
Nous avons montré comment créer une visualisation multicouches et multipanneaux (mais à graphique unique) des données de la Banque mondiale.
Exercices :
- Sur chaque graphique de série temporelle, ajoutez un point dont la taille est proportionnelle à la population, comme dans le nuage de points. Les points ne doivent apparaître que lorsque le pays est sélectionné, et cliquer sur un point doit désélectionner ce pays.
- Ajoutez des étiquettes de texte au graphique de la série temporelle situé à droite, avec le nom de chaque pays. L’étiquette ne doit apparaître que lorsque le pays est sélectionné, et disparaître lorsqu’on clique sur l’étiquette.
- Ajoutez une étiquette de texte au nuage de points pour indiquer l’année sélectionnée.
- Ajoutez des étiquettes au nuage de points, avec le nom de chaque pays. L’étiquette ne doit apparaître que lorsque le pays est sélectionné, et disparaître lorsqu’on clique sur l’étiquette.
Dans le chapitre 9 nous vous expliquerons comment visualiser les données sur les vélos à Montréal.