library(animint2)
if(!requireNamespace('maps'))install.packages('maps')Loading required namespace: mapsUSpolygons <- map_data("state")Ce chapitre présente l’ensemble des nouvelles fonctionnalités qu’animint2 ajoute à la grammaire des graphiques. Après l’avoir lu, vous saurez personnaliser vos graphiques animint2 en utilisant :
aes() href, tooltip et id pour définir les caractéristiques propres à l’observation ;
clickSelects et showSelected pour spécifier plusieurs variables de sélection simultanément ;
chunk_vars spécifique au geom ;
color_off, fill_off, et alpha_off pour contrôler l’affichage de l’état de la sélection ;
help et title, pour le texte affiché dans la visite guidée ;
aes())Cette section explique les nouveaux aes() reconnus par animint2.
aes() introduits précédemmentDiscutons d’abord des nouveaux aes() déjà introduits dans les chapitres précédents.
aes(key) a été présenté au chapitre 3 ; il sert à désigner une variable à utiliser pour obtenir des transitions fluides et interprétables.
aes(href)
Il est possible d’ajouter un hyperlien avec aes(href). Par exemple, on peut insérer un lien vers la page Wikipédia de chaque État sur une carte des États-Unis. On commence par charger les données pour tracer les frontières des États.
library(animint2)
if(!requireNamespace('maps'))install.packages('maps')Loading required namespace: mapsUSpolygons <- map_data("state")Notez, dans le code ci-dessus, qu’il faut installer le package maps pour obtenir les données. On utilise ensuite le code pour tracer la carte. L’utilisation de geom_polygon() avec aes(href) créera des hyperliens vers la page Wikipédia de chaque État.
animint(
map=ggplot()+
ggtitle("Cliquez sur un État pour lire sa page Wikipédia")+
coord_equal()+
geom_polygon(aes(
x=long, y=lat, group=group,
href=paste0("http://fr.wikipedia.org/wiki/", region)),
data=USpolygons, fill="black", colour="grey"))Essayez de cliquer sur un État dans la visualisation de données ci-dessus. Vous devriez voir la page Wikipédia correspondante s’ouvrir dans un nouvel onglet.
aes(tooltip)
Les infobulles sont des petites fenêtres d’information textuelle qui apparaissent lorsque vous survolez un élément avec le curseur. Dans animint(), vous pouvez utiliser aes(tooltip) pour définir le message à afficher pour chaque observation. Par exemple, nous l’utilisons pour afficher la population et le nom du pays dans le nuage de points des données de la Banque mondiale ci-dessous :
Placez le curseur sur l’un des points. Vous devriez voir apparaître une petite boîte contenant le nom du pays et la population pour ce point.
Notez qu’une infobulle de forme « valeur variable » est définie par défaut pour chaque geom avec clickSelects. Par exemple, un geom avec clickSelects="année" affiche l’infobulle par défaut « année 1984 » pour une observation correspondant à cette période. Vous pouvez modifier cette valeur par défaut en spécifiant explicitement aes(tooltip).
aes(id)
Puisque tout ce qui est tracé par animint() est affiché comme un élément SVG dans une page web (SVG-authors 2026), vous pourriez vouloir spécifier un élément attribut HTML id (W3Schools 2026) à l’aide de aes(id) comme ci-dessous :
animint(
map=ggplot()+
ggtitle("chaque État/région/groupe a un id unique")+
coord_equal()+
geom_polygon(aes(
x=long, y=lat, group=group,
id=gsub(" ", "_", paste(region, group))),
data=USpolygons, fill="black", colour="grey"))Notez que pour qu’un identifiant soit bien défini, il ne doit pas contenir d’espaces ; nous utilisons donc gsub pour convertir les espaces en tirets bas (underscores). Notez également que paste est utilisé pour ajouter un numéro de groupe, car il peut y avoir plus d’un polygone par État/région, et chaque identifiant doit être unique sur une page web. Les développeurs d’animint2 utilisent cette fonctionnalité pour tester le code JavaScript (Animint-developers 2026) (en anglais).
aes(group)
La compression de données améliore le téléchargement et le stockage des grands jeux de données avec des structures répétées à travers les sous-ensembles showSelected. Dans ggplot2, on utilise aes(group) pour définir des courbes (geom_line() et geom_path()) et des polygones (geom_polygon() et geom_ribbon()). Dans animint2, on peut également utiliser aes(group) pour définir la compression de données, même avec d’autres geoms qui n’acceptent pas aes(group) dans ggplot2 (comme geom_point()). Cette utilisation est avantageuse pour améliorer l’efficacité du téléchargement et du stockage, quand il y a les mêmes données pour chaque groupe, à travers différents sous-ensembles showSelected. Considérons l’exemple suivant qui présente des données mensuelles pour certaines années et certains pays :
library(data.table)
mois.dt <- rbind(
data.table(année=1, mois=10:12),
data.table(année=2, mois=1:12),
data.table(année=3, mois=1:5))
set.seed(1)
(pays.dt <- rbind(
data.table(mois.dt, pays="États-Unis")[, valeur := rnorm(.N, 5)][-.N],
data.table(mois.dt, pays="Canada")[, valeur := rnorm(.N, 9)][-1])) année mois pays valeur
1: 1 10 États-Unis 4.373546
2: 1 11 États-Unis 5.183643
---
37: 3 4 Canada 10.100025
38: 3 5 Canada 9.763176La sortie ci-dessus affiche un tableau avec une ligne par mois et par pays. Nous utilisons ces données dans la visualisation ci-dessous :
animint(
ggplot()+
geom_point(aes(
mois, valeur, color=pays),
data=pays.dt,
showSelected="année"))La visualisation ci-dessus contient deux colonnes ayant des valeurs communes pour toutes les années et pourraient être compressées :
pays est soit États-Unis soit Canada ;mois est un nombre entier de 1 à 12.Pour analyser les compressions possibles, nous définissons une fonction auxiliaire qui calculera la visualisation, et fera un résumé de ses fichiers TSV.
animint_tsv <- function(...){
vis <- animint(...)
info <- animint2dir(vis, "ch06tsv")
tsv.files <- Sys.glob(file.path(info$out.dir,"*.tsv"))
sapply(tsv.files, fread, simplify=FALSE)
}Ci-dessous, nous utilisons cette fonction pour analyser la visualisation précédente :
animint_tsv(
ggplot()+
geom_point(aes(
mois, valeur, color=pays),
data=pays.dt,
showSelected="année"))$`ch06tsv/geom1_point_plot1_chunk1.tsv`
colour x y showSelected1 showSelected2 fill
1: #00BFC4 10 4.373546 1 États-Unis #00BFC4
2: #00BFC4 11 5.183643 1 États-Unis #00BFC4
---
37: #F8766D 4 10.100025 3 Canada #F8766D
38: #F8766D 5 9.763176 3 Canada #F8766DLa sortie ci-dessous présente une liste contenant un seul tableau de données, ce qui signifie qu’il n’y a qu’un seul fichier TSV, car il s’agit d’un ensemble de données relativement petit. La compression n’est pas utilisée lorsqu’un seul fichier TSV est généré. Pour explorer la compression, nous forçons la création d’un fichier distinct pour chaque année en ajoutant le paramètre de chunk_vars.
animint_tsv(
ggplot()+
geom_point(aes(
mois, valeur, color=pays),
data=pays.dt,
chunk_vars="année",
showSelected="année"))$`ch06tsv/geom1_point_plot1_chunk1.tsv`
colour x y showSelected2 fill
1: #00BFC4 10 4.373546 États-Unis #00BFC4
2: #00BFC4 11 5.183643 États-Unis #00BFC4
3: #00BFC4 12 4.164371 États-Unis #00BFC4
4: #F8766D 11 9.782136 Canada #F8766D
5: #F8766D 12 9.074565 Canada #F8766D
$`ch06tsv/geom1_point_plot1_chunk2.tsv`
colour x y showSelected2 fill
1: #00BFC4 1 6.595281 États-Unis #00BFC4
2: #00BFC4 2 5.329508 États-Unis #00BFC4
---
23: #F8766D 11 8.946195 Canada #F8766D
24: #F8766D 12 7.622940 Canada #F8766D
$`ch06tsv/geom1_point_plot1_chunk3.tsv`
colour x y showSelected2 fill
1: #00BFC4 1 4.955066 États-Unis #00BFC4
2: #00BFC4 2 4.983810 États-Unis #00BFC4
---
8: #F8766D 4 10.100025 Canada #F8766D
9: #F8766D 5 9.763176 Canada #F8766DLa sortie ci-dessus est une liste de trois tableaux de données, un pour chaque année. Lorsqu’on la compare à celle de l’exemple précédent, on voit qu’il manque une colonne showSelected1, qui était utilisée pour les valeurs d’année, mais qui devient inutile, puisque la colonne n’aurait qu’un seule valeur par fichier. Pour activer la compression des données, nous utilisons aes(group=pays) dans le code ci-dessous. Le code va alors tenter la compression, en cherchant des données pour chaque pays, qui sont répétées pour chaque année.
animint_tsv(
ggplot()+
geom_point(aes(
mois, valeur, color=pays, group=pays),
data=pays.dt,
chunk_vars="année",
showSelected="année"))$`ch06tsv/geom1_point_plot1_chunk1.tsv`
group x y
1: 1 11 9.782136
2: 1 12 9.074565
3: 2 10 4.373546
4: 2 11 5.183643
5: 2 12 4.164371
$`ch06tsv/geom1_point_plot1_chunk2.tsv`
group x y
1: 1 1 7.010648
2: 1 2 9.619826
---
23: 2 11 2.785300
24: 2 12 6.124931
$`ch06tsv/geom1_point_plot1_chunk3.tsv`
group x y
1: 1 1 8.585005
2: 1 2 8.605710
---
8: 2 3 5.943836
9: 2 4 5.821221
$`ch06tsv/geom1_point_plot1_chunk_common.tsv`
group colour fill showSelected2
1: 1 #F8766D #F8766D Canada
2: 2 #00BFC4 #00BFC4 États-UnisLa sortie ci-dessous est une liste de quatre tableaux de données qui présentent une compression des données propres aux groupes (pays), qui sont répétées à travers les sous-ensembles showSelected (années).
x et y ont les valeurs diffèrentes pour chaque groupe (x et y sont différents pour chaque pays et année).colour, fill et showSelected2 contiennent les valeurs propres à chaque pays, quelle que soit l’année.Ci-dessous, nous utilisons aes(group=mois) à titre de comparaison :
animint_tsv(
ggplot()+
geom_point(aes(
mois, valeur, color=pays, group=mois),
data=pays.dt,
chunk_vars="année",
showSelected="année"))$`ch06tsv/geom1_point_plot1_chunk1.tsv`
group colour x y showSelected2 fill
1: 10 #00BFC4 10 4.373546 États-Unis #00BFC4
2: 11 #00BFC4 11 5.183643 États-Unis #00BFC4
3: 11 #F8766D 11 9.782136 Canada #F8766D
4: 12 #00BFC4 12 4.164371 États-Unis #00BFC4
5: 12 #F8766D 12 9.074565 Canada #F8766D
$`ch06tsv/geom1_point_plot1_chunk2.tsv`
group colour x y showSelected2 fill
1: 1 #00BFC4 1 6.595281 États-Unis #00BFC4
2: 1 #F8766D 1 7.010648 Canada #F8766D
---
23: 12 #00BFC4 12 6.124931 États-Unis #00BFC4
24: 12 #F8766D 12 7.622940 Canada #F8766D
$`ch06tsv/geom1_point_plot1_chunk3.tsv`
group colour x y showSelected2 fill
1: 1 #00BFC4 1 4.955066 États-Unis #00BFC4
2: 1 #F8766D 1 8.585005 Canada #F8766D
---
8: 4 #F8766D 4 10.100025 Canada #F8766D
9: 5 #F8766D 5 9.763176 Canada #F8766DLa sortie ci-dessus est une liste de trois tableaux de données, sans fichier TSV de données communes. Dans ce cas, la compression ne s’applique pas, puisqu’il n’y a qu’une colonne (x) avec une valeur commune pour chaque groupe/mois, d’une année à l’autre. Pour activer la compression avec group=mois, il faut au moins deux variables communes à chaque groupe d’une année à l’autre, comme le montre l’exemple ci-dessous dans lequel nous avons modifié aes(color) :
animint_tsv(
ggplot()+
geom_point(aes(
mois, valeur, color=mois, group=mois),
data=pays.dt,
chunk_vars="année",
showSelected="année"))$`ch06tsv/geom1_point_plot1_chunk1.tsv`
group y
1: 1 6.595281
2: 1 7.010648
---
23: 12 6.124931
24: 12 7.622940
$`ch06tsv/geom1_point_plot1_chunk2.tsv`
group y
1: 1 4.955066
2: 1 8.585005
---
8: 4 10.100025
9: 5 9.763176
$`ch06tsv/geom1_point_plot1_chunk3.tsv`
group y
1: 10 4.373546
2: 11 5.183643
3: 11 9.782136
4: 12 4.164371
5: 12 9.074565
$`ch06tsv/geom1_point_plot1_chunk_common.tsv`
group colour fill x
1: 1 #132B43 #132B43 1
2: 2 #183652 #183652 2
---
11: 11 #4FA4E5 #4FA4E5 11
12: 12 #56B1F7 #56B1F7 12La sortie ci-dessus est une liste de quatre tableaux de données qui présentent un autre exemple de compression.
y avec valeurs diffèrentes pour chaque groupe/mois.colour, fill et x contiennent des valeurs propres à chaque groupe/mois, qui sont répétées d’une année à l’autre.Ci-dessous, nous présentons un exemple de compression à l’aide de geom_path(), dans lequel nous utilisons également aes(group) pour déterminer les différentes courbes. De plus, nous redéfinissons color et group pour pays :
$`ch06tsv/geom1_path_plot1_chunk1.tsv`
group x y
1: 1 11 9.782136
2: 1 12 9.074565
3: 2 10 4.373546
4: 2 11 5.183643
5: 2 12 4.164371
$`ch06tsv/geom1_path_plot1_chunk2.tsv`
group x y
1: 1 1 7.010648
2: 1 2 9.619826
---
23: 2 11 2.785300
24: 2 12 6.124931
$`ch06tsv/geom1_path_plot1_chunk3.tsv`
group x y
1: 1 1 8.585005
2: 1 2 8.605710
---
8: 2 3 5.943836
9: 2 4 5.821221
$`ch06tsv/geom1_path_plot1_chunk_common.tsv`
group colour showSelected2
1: 1 #F8766D Canada
2: 2 #00BFC4 États-UnisOn voit ci-dessus un tableau des données communes avec des colonnes group, colour et showSelected2. Cette compression est identique à celle du premier exemple présenté plus haut (valeur constante pour chaque groupe/pays d’une année à l’autre).
Les exemples précédents démontrent comment la compression peut être utilisée lorsque chaque groupe possède des valeurs scalaires communes à tous les sous-ensembles showSelected. Il existe une autre méthode de compression lorsque chaque groupe possède un vecteur de valeurs commun pour tous les sous-ensembles. Nous allons y recourir, car nous voulons que x soit considéré comme une donnée commune dans l’exemple du geom_path(). Pour ce faire nous créons un nouvel ensemble de données présentant les caractéristiques suivantes :
x=mois identique pour chaque groupe ;y=valeur.Nous créons un nouvel ensemble de données dont certaines valeurs de y sont manquantes. Il est présenté dans le code ci-dessous. Nous utilisons CJ (cross join) pour générer un tableau de données de 72 lignes (une par combinaison de pays, années et mois).
(na.dt <- pays.dt[CJ(pays,année,mois,unique=TRUE), on=.NATURAL]) année mois pays valeur
1: 1 1 Canada NA
2: 1 2 Canada NA
---
71: 3 11 États-Unis NA
72: 3 12 États-Unis NAComme prévu, la sortie ci-dessus affiche NA dans la colonne valeur. Ci-dessous, nous utilisons ce tableau de données et appliquons le même code geom_path() que dans l’exemple précédent.
$`ch06tsv/geom1_path_plot1_chunk1.tsv`
group y row_in_group na_group
1: 1 9.782136 11 10
2: 1 9.074565 12 10
3: 2 4.373546 10 9
4: 2 5.183643 11 9
5: 2 4.164371 12 9
$`ch06tsv/geom1_path_plot1_chunk2.tsv`
group y
1: 1 7.010648
2: 1 9.619826
---
23: 2 2.785300
24: 2 6.124931
$`ch06tsv/geom1_path_plot1_chunk3.tsv`
group y
1: 1 8.585005
2: 1 8.605710
---
8: 2 5.943836
9: 2 5.821221
$`ch06tsv/geom1_path_plot1_chunk_common.tsv`
group colour showSelected2 x
1: 1 #F8766D Canada 1
2: 1 #F8766D Canada 2
---
23: 2 #00BFC4 États-Unis 11
24: 2 #00BFC4 États-Unis 12La sortie ci-dessus présente un tableau de données communes avec des colonnes group, colour, showSelected2 et x pour lesquels :
x contient des valeurs différentes dans chaque ligne, indiquant qu’il s’agit du vecteur de valeurs commun pour chaque pays, d’une année à l’autre.colour et showSelected2 ont la même valeur dans chaque ligne. Ce sont les valeurs uniques qui sont communes à chaque pays, d’une année à l’autre.Notez également que le fichier chunk1.tsv contient les colonnes row_in_group et na_group utilisées pour joindre ces données au fichier de données communes. Pour chunk2.tsv et chunk3.tsv ces colonnes sont inutiles, car il n’y a pas de valeurs manquantes au début de la séquence de données.
Les exemples précédents montrent que plusieurs paramètres permettent la compression des données :
chunk_vars définit les variables showSelected utilisées pour diviser les données dans des fichiers TSV.aes(group) est défini pour une variable dont les groupes possèdent des données communes.NA) sont utilisées pour inclure un vecteur de valeurs dans le fichier de données communes, tandis que les valeurs manquantes implicites (suppression de lignes) conviennent lorsque le fichier de données communes ne doit contenir que des valeurs constantes.Le meilleur choix de ces paramètres dépend de l’ensemble de données dans votre visualisation. En général, on choisit celui qui minimise l’espace disque utilisé et réduit le temps de téléchargement. Pour quelques exemples présentant de plus grands ensembles de données, consultez la galérie HiC (Hocking 2025).
clickSelects et showSelected nommésLe chapitre 3 introduit showSelected pour désigner un geom qui n’affiche que le sous-ensemble sélectionné de ses données.
Le chapitre 4 introduit clickSelects pour désigner un geom sur lequel on peut cliquer pour modifier une variable de sélection.
En général, les noms de sélecteurs sont définis dans showSelected ou clickSelects. Par exemple, showSelected=c("année", "pays") signifie que deux variables de sélection (année et pays) seront créées . Cependant, cette méthode est peu pratique si vous avez de nombreux sélecteurs dans votre visualisation des données. Considérons le cas théorique suivant (le code présenté dans cette section n’est pas directement exécutable). Supposons que vous souhaitez utiliser 20 noms de variables de sélecteurs différents, selector1value… selector20value. La façon habituelle de définir votre visualisation de données serait la suivante :
vis <- list(
points=ggplot()+
geom_point(clickSelects="selector1value", data=data1)+
...
<!-- comment -->
geom_point(clickSelects="selector20value", data=data20)
)Cependant, c’est un mauvaise méthode, car elle contrevient au principe DRY (Don’t Repeat Yourself). Une autre approche consiste à utiliser une boucle for.
vis <- list(points=ggplot())
for(selector.name in paste0("selector", 1:20, "value")){
data.for.selector <- all.data.list[[selector.name]]
<!-- comment -->
vis$points <- vis$points +
geom_point(clickSelects=selector.name, data=data.for.selector)
}Cette approche est elle aussi inadéquate : elle ralentit la construction de vis, et la visualisation compilée prend potentiellement beaucoup d’espace disque, puisqu’il y a au moins un fichier TSV créé pour chaque geom_point(). La méthode à privilégier est d’ajouter des noms dans le vecteur utilisé pour clickSelects ou showSelected. Les noms doivent être utilisés pour indiquer la colonne qui contient le nom de la variable du sélecteur. Par exemple :
vis <- list(
points=ggplot()+
geom_point(
clickSelects=c(selector.name="selector.value"),
data=all.data)
)Le compilateur d’animint2 parcourt all.data$selector.name et crée une variable de sélection pour chacune des valeurs distinctes. Lorsqu’on clique sur l’un des points, la variable correspondant est mis à jour avec la valeur indiquée par all.data$selector.value.
De la même manière, vous pouvez ajouter des noms au vecteur showSelected, au lieu de créer plusieurs geoms, ayant une valeur différente pour showSelected.
Cette fonctionnalité évite non seulement les répétitions dans la définition de la visualisation des données, mais elle augmente aussi l’efficacité sur le plan computationnel. Pour un exemple détaillé avec des mesures de temps d’exécution et d’espace disque, voir le chapitre 14.
Dans animint2, il existe plusieurs options de personnalisation des geoms. Par exemple, chunk_vars permet de spécifier la division des ensembles de données pour leur stockage sur disque. Quant aux paramètres *_off, ils sont utilisés pour définir l’affichage d’un geom clickSelects lorsqu’il n’est pas sélectionné. De plus, les paramètres help et title permettent d’ajouter des informations à la visite guidée.
chunk_vars
Le paramètre chunk_vars définit les variables de sélection qui sont utilisées pour diviser l’ensemble de données en morceaux distincts (fichiers TSV) à télécharger. Un fichier TSV est créé pour chaque combinaison de valeurs des variables chunk_vars. Plus le nombre de variables de sélection spécifiées dans chunk_vars est élevé, plus l’ensemble de données sera divisé en fichiers TSV distincts, chacun de taille plus petite.
L’option chunk_vars doit être spécifiée comme argument d’une fonction comme geom_point(), et sa valeur doit être un sous-ensemble des variables de sélection. Lorsque chunk_vars=character(0), soit un vecteur de caractères de longueur nulle, toutes les données sont stockées dans un seul fichier TSV. À l’autre extrême, lorsque chunk_vars contient toutes les variables de showSelected, un fichier TSV est créé pour chaque combinaison des valeurs de ces variables (beaucoup de fichiers TSV, chacun de petite taille).
En général, le compilateur choisit une valeur par défaut raisonnable pour chunk_vars, mais vous pouvez la spécifier si la visualisation se charge lentement ou occupe trop d’espace sur le disque. Si la visualisation se charge lentement, vous devriez ajouter des variables de sélection à chunk_vars pour réduire la taille du premier fichier TSV à télécharger. Si la visualisation occupe trop d’espace, vous pouvez retirer les variables de sélection de chunk_vars pour réduire le nombre de fichiers TSV. De nombreux petits fichiers TSV peuvent occuper plus d’espace disque qu’un seul fichier TSV, car certains systèmes de fichiers stockent une quantité constante de métadonnées pour chaque fichier.
Pour illustrer l’utilisation de chunk_vars, considérons la visualisation suivante de l’ensemble de données breakpoints :
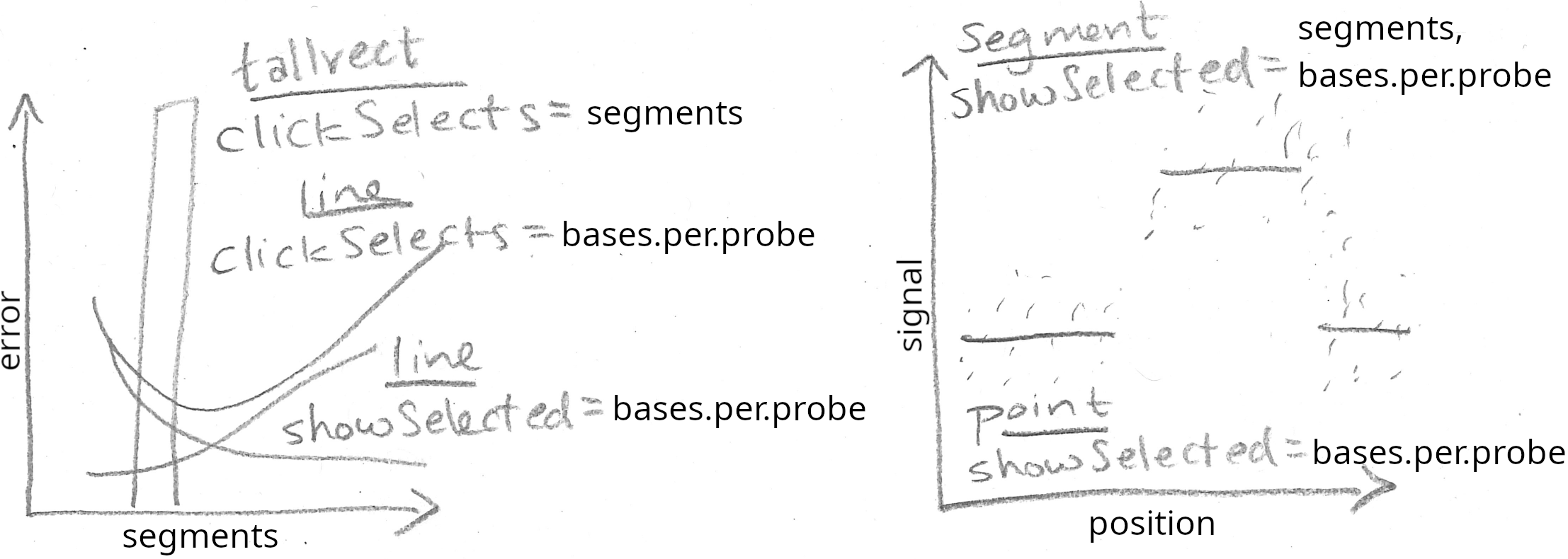
L’esquisse ci-dessus est composée de deux graphiques. Nous commençons par créer le graphique des courbes d’erreurs situé à gauche.
data(breakpoints)
only.error <- subset(breakpoints$error, type=="E")
only.segments <- subset(only.error,bases.per.probe==bases.per.probe[1])
library(data.table)
fp.fn.names <- rbind(
data.table(error.type="false positives", type="FP"),
data.table(error.type="false negatives", type=c("I", "FN")))
error.dt <- data.table(breakpoints$error)
error.type.dt <- error.dt[fp.fn.names, on=list(type)]
fp.fn.dt <- error.type.dt[, list(
error.value=sum(error)
), by=.(error.type, segments, bases.per.probe)]
errorPlot <- ggplot()+
ggtitle("selectionner les données et les segments")+
theme_bw()+
geom_tallrect(aes(
xmin=segments-0.5, xmax=segments+0.5),
clickSelects="segments",
data=only.segments,
alpha=1/2)+
geom_line(aes(
segments, error.value, color=error.type,
group=paste(bases.per.probe, error.type)),
showSelected="bases.per.probe",
data=fp.fn.dt,
size=5)+
scale_color_manual(values=c(
"false positives"="red", "false negatives"="blue"))+
geom_line(aes(
segments, error, group=bases.per.probe),
clickSelects="bases.per.probe",
data=only.error,
size=4)+
scale_x_continuous(breaks=c(1, 6, 10, 20))
errorPlot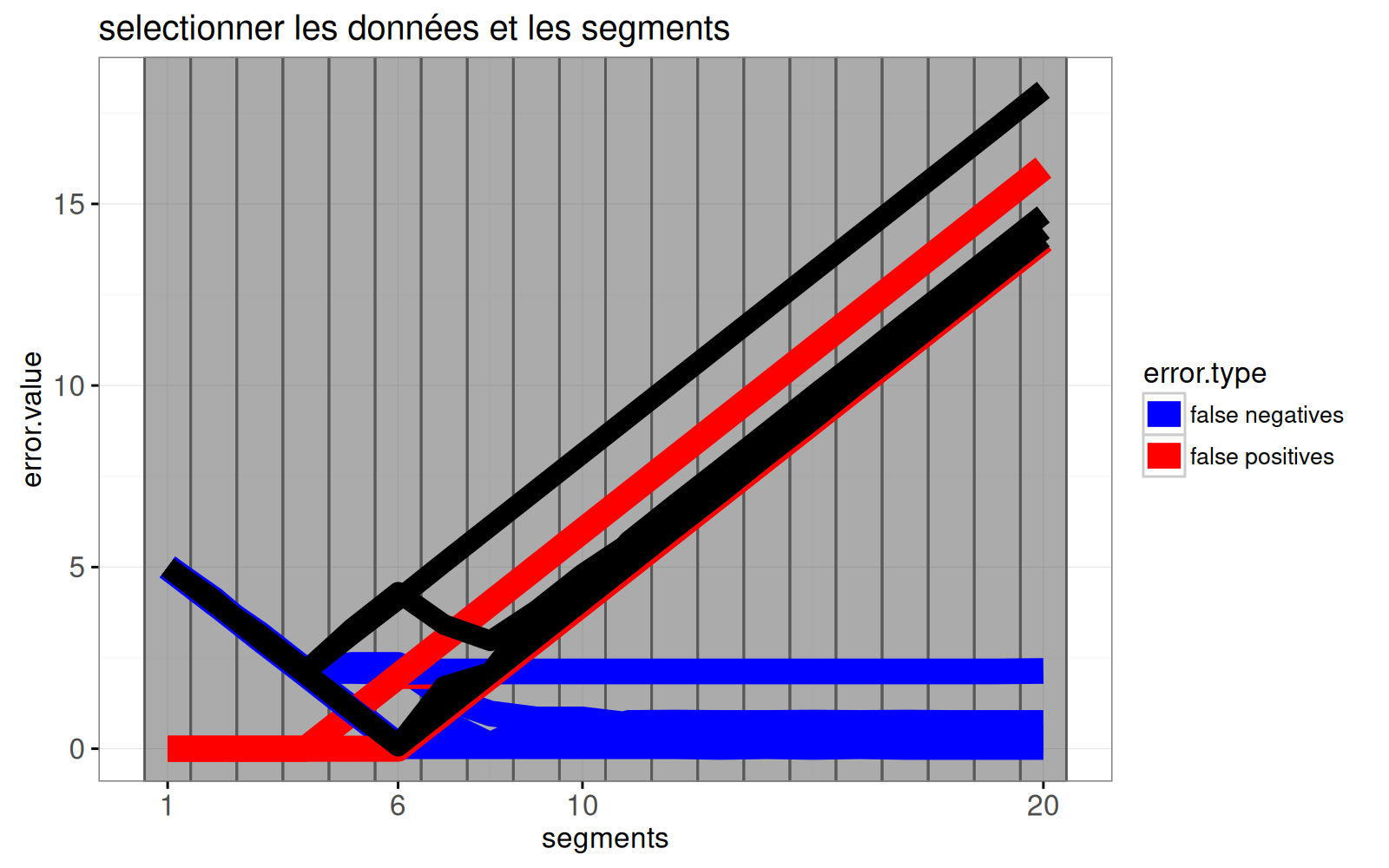
Le graphique ci-dessus comprend un geom_tallrect() avec clickSelects="segments" et un geom_line() avec clickSelects="bases.per.probe". Il servira à sélectionner les données et le modèle dans le graphique ci-dessous.
signalPlot <- ggplot()+
theme_bw()+
theme(panel.margin=grid::unit(0, "lines"))+
theme_animint(last_in_row=TRUE)+
geom_point(aes(
position/1e5, signal),
showSelected="bases.per.probe",
data=breakpoints$signals)+
geom_segment(aes(
first.base/1e5, mean, xend=last.base/1e5, yend=mean),
showSelected=c("segments", "bases.per.probe"),
color="green",
data=breakpoints$segments)
signalPlot+facet_grid(segments ~ bases.per.probe)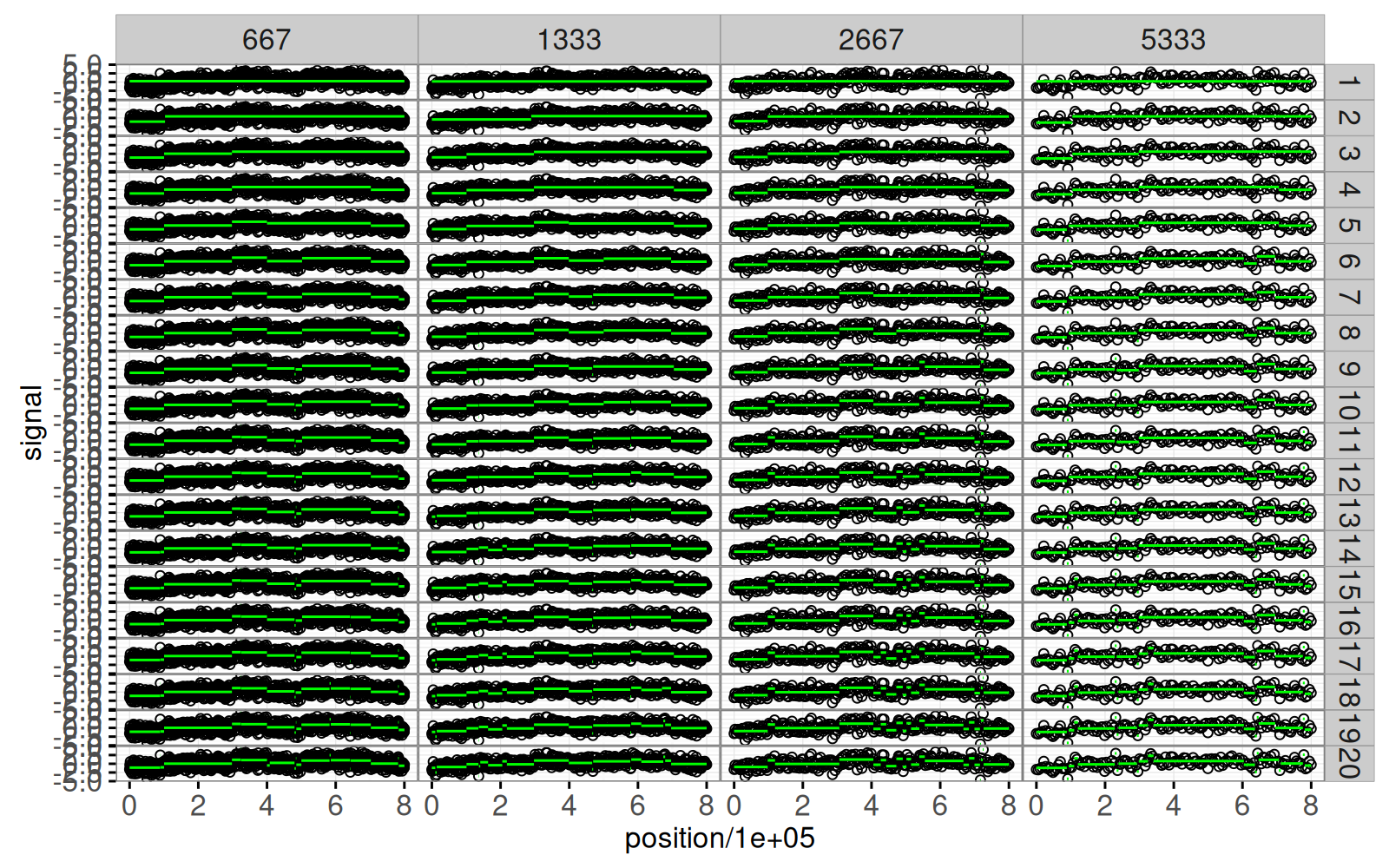
Le graphique non interactif ci-dessus comporte 80 facets, un pour chaque combinaison des deux variables showSelected, c’est-à-dire bases.per.probe et segments. Nous présentons ci-dessous une version interactive dans laquelle un seul de ces facets sera affiché.
(vis.chunk.vars <- animint(
errorPlot,
signal=signalPlot+
geom_vline(aes(
xintercept=base/1e5),
showSelected=c("segments", "bases.per.probe"),
color="green",
chunk_vars=character(),
linetype="dashed",
data=breakpoints$breaks)))Cliquez sur le bouton « Show download status table », vous devriez voir des décomptes de chunks (fichiers TSV). Notez que geom6_vline_signal n’a qu’un seul morceau, puisque chunk_vars=character() est spécifié pour l’élément geom_vline() dans le code R ci-dessus. Si une autre valeur de chunk_vars était spécifiée, cela créerait un nombre différent de fichiers TSV, mais l’apparence de la visualisation de données devrait rester la même.
Ci-dessous, nous utilisons le programme en ligne de commande du pour déterminer l’utilisation du disque de la visualisation pour différents choix de chunk_vars.
tsvSizes <- function(segment.chunk.vars){
vis <- list(
error=errorPlot,
signal=signalPlot+
geom_vline(aes(
xintercept=base/1e5),
showSelected=c("segments", "bases.per.probe"),
color="green",
chunk_vars=segment.chunk.vars,
linetype="dashed",
data=breakpoints$breaks)
)
info <- animint2dir(vis, open.browser=FALSE)
cmd <- paste("du -ks", info$out.dir)
kb.dt <- fread(cmd=cmd)
setnames(kb.dt, c("kb", "dir"))
tsv.vec <- Sys.glob(paste0(info$out.dir, "/*.tsv"))
is.geom6 <- grepl("geom6", tsv.vec)
data.frame(
kb=kb.dt$kb, geom6.tsv=sum(is.geom6), other.tsv=sum(!is.geom6))
}
chunk_vars_list <- list(
neither=c(),
bases.per.probe=c("bases.per.probe"),
segments=c("segments"),
both=c("segments", "bases.per.probe"))
sizes.list <- lapply(chunk_vars_list, tsvSizes)
(sizes <- do.call(rbind, sizes.list)) kb geom6.tsv other.tsv
neither 832 1 12
bases.per.probe 836 5 12
segments 892 19 12
both 1120 76 12Le tableau ci-dessus indique le nombre de kilo-octets pour la visualisation des données, ainsi que le nombre de fichiers TSV pour geom6_vline_signal et les autres geoms. Notez comment le choix de chunk_vars affecte le nombre de fichiers TSV et l’utilisation de l’espace disque. Puisque chunk_vars n’a été spécifié que pour les geom6_vline_signal, le nombre de fichiers TSV pour les autres geoms ne change pas. Lorsque segments et bases.per.probe sont tous les deux spécifiés pour chunk_vars, il y a 76 fichiers TSV pour geom6_vline_signal, et la visualisation des données occupe 1120 kilo-octets. En revanche, chunk_vars=character() ne produit qu’un seul fichier TSV pour geom6_vline_signal, et la visualisation des données occupe 832 kilo-octets.
En conclusion, l’option chunk_vars spécifique au geom détermine le nombre de fichiers TSV créés pour chaque geom. Lors du choix de la valeur de chunk_vars, vous devez tenir compte à la fois de l’utilisation du disque et du temps de chargement. Un petit nombre de gros fichiers occupe moins d’espace disque, mais leur téléchargement est plus lent que celui de nombreux petits fichiers.
Les valeurs par défaut sont raisonnables pour l’affichage de l’état de sélection :
rect ou un tile avec clickSelects, le noir est utilisé pour color/border afin de montrer les éléments qui sont sélectionnés, et le transparent pour les éléments qui ne sont pas sélectionnés.
clickSelects, nous utilisons une opacité complète alpha pour afficher les éléments sélectionnés, et une opacité réduite alpha-0.5 pour les éléments non sélectionnés.Les valeurs par défaut expliquées plus haut sont illustrées dans le premier graphique ci-dessous. Elles peuvent être personnalisées en utilisant les paramètres du geom alpha_off, fill_off et color_off comme dans le code ci-dessous :
N <- 3
set.seed(1)
demo_df <- data.frame(i=1:N, num=rnorm(N,2))
animint(
defaults=ggplot()+
ggtitle("Paramètres par défaut, sans *_off")+
geom_tile(aes(
i, 0),
size=5,
clickSelects="i",
data=demo_df)+
geom_point(aes(
i, num),
size=5,
clickSelects="i",
data=demo_df),
off=ggplot()+
ggtitle("Paramètres définis : alpha_off, fill_off, color_off")+
geom_tile(aes(
i, 0, fill=i),
clickSelects="i",
color="red",
color_off="pink",
size=5,
data=demo_df)+
geom_point(aes(
i, num),
size=5,
alpha=0.5,
alpha_off=0.1,
clickSelects="i",
data=demo_df)+
geom_point(aes(
i, -num),
size=5,
alpha=1,
alpha_off=1,
color="red",
color_off="black",
fill="grey",
fill_off="white",
clickSelects="i",
data=demo_df))Notez que lorsque vous utilisez l’une de ces propriétés visuelles dans le mapping aes, elle ne doit pas être spécifiée en tant que paramètre geom. Par exemple, dans le tile ci-dessus, nous avons utilisé aes(fill), donc fill et fill_off ne doivent pas être spécifiés comme paramètres pour ce geom (afin qu’il soit clair que fill sert à afficher les valeurs des données, et non l’état de sélection).
Depuis janvier 2025, animint2 prend en charge les visites guidées qui affichent des informations sur les interactions possibles avec chaque geom. Pour personnaliser l’affichage pour chaque geom, vous pouvez spécifier les paramètres help et title, comme dans le code ci-dessous :
animint(
scatter=ggplot()+
geom_point(aes(
x=espérance.de.vie, y=taux.de.fertilité, color=région),
size=5,
showSelected="année",
clickSelects="pays",
help="Un point pour chaque pays dans l'année sélectionnée",
alpha=0.7,
data=BanqueMondiale)+
geom_text(aes(
x=espérance.de.vie, y=taux.de.fertilité, label=pays),
data=BanqueMondiale,
title="Pays sélectionné",
showSelected=c("année","pays")),
first=list(
pays="France",
année=1980))Dans le code ci-dessus, nous spécifions help pour le geom_point(), qui contrôle le sous-texte affiché pour ce geom une fois cliqué le bouton « Start Tour » au bas de la visualisation. Après avoir cliqué sur le bouton « Next », on peut voir le title spécifié dans le code s’afficher en haut de la fenêtre de visite, pour le geom_text(). Ce mécanisme peut être utilisé pour fournir des informations supplémentaires aux utilisateurs de la visualisation pour faciliter leur compréhension de l’affichage et des interactions possibles.
Cette section traite des options propres au ggplot d’une visualisation de données. La fonction theme_animint() est utilisée pour attacher des options animint2 aux objets ggplot.
Les options width et height permettent de spécifier les dimensions (en pixels) d’un ggplot affiché par animint(). Par exemple, considérons cette version remaniée du graphique des États-Unis :
animint(
map=ggplot()+
theme_animint(width=750, height=500)+
theme(
axis.line=element_blank(),
axis.text=element_blank(),
axis.ticks=element_blank(),
axis.title=element_blank(),
panel.border=element_blank(),
panel.background=element_blank(),
panel.grid.major=element_blank(),
panel.grid.minor=element_blank())+
geom_polygon(aes(
x=long, y=lat, group=group),
data=USpolygons, fill="black", colour="grey"))Notez que le graphique ci-dessus a été généré avec une largeur de 750 pixels et une hauteur de 500 pixels, en raison des options theme_animint. Si l’une de ces options n’est pas définie pour un ggplot, animint() utilise une valeur par défaut de 400 pixels.
Notez également que theme a été utilisé pour spécifier plusieurs éléments vides. Cela a pour effet de supprimer les axes et l’arrière-plan, ce qui est généralement utile pour générer des cartes.
L’échelle scale_size_animint doit être utilisée dans tous les ggplots où vous précisez aes(size). Pour comprendre pourquoi, considérons les exemples suivants :
nuage1975 <- ggplot()+
geom_point(
aes(x=espérance.de.vie, y=taux.de.fertilité, size=population),
BanqueMondiale1975,
color="red",
fill="black")
(vis.scale.size <- animint(
ggplotDefault=nuage1975+
ggtitle("Aucune échelle spécifiée"),
animintDefault=nuage1975+
ggtitle("scale_size_animint()")+
scale_size_animint(),
animintOptions=nuage1975+
ggtitle("scale_size_animint(pixel.range, breaks)")+
scale_size_animint(pixel.range=c(5, 15), breaks=10^(10:1))))Le premier ggplot ci-dessus n’a pas d’échelle définie, il utilise donc l’échelle par défaut de ggplot2, ce qui pose deux problèmes. Le premier est que tous les pays semblent avoir à peu près la même taille, à l’exception des deux plus grands. Ce problème peut être résolu en ajoutant simplement scale_size_animint() au ggplot pour obtenir le deuxième graphique ci-dessus. Cependant, un second problème apparaît : les entrées de la légende ne montrent pas toute l’étendue des données. On résout ce problème dans le troisième graphique ci-dessus, en spécifiant manuellement l’option breaks à utiliser pour les entrées de légende. Notez que l’argument pixel.range peut également être utilisé pour définir le rayon du plus grand et du plus petit cercle.
La syntaxe de définition des axes et de la taille du texte de la légende(en pixels) est pratiquement la même que celle de ggplot2. À l’intérieur de theme, vous pouvez simplement utiliser des nombres pour modifier la taille de la police, ou utiliser rel() pour définir la taille relative.
nuage1975 <- ggplot()+
geom_point(aes(
x=espérance.de.vie, y=taux.de.fertilité, color=région),
data=BanqueMondiale1975)
(vis.text.size <- animint(
animintDefault=nuage1975+
theme_animint(width=500, height=500)+
ggtitle("Aucun axe ni taille de légende spécifiés"),
animintAxesOptions=nuage1975+
theme_animint(width=500, height=500)+
theme(axis.text=element_text(size=20))+
ggtitle("axis.text=element_text(size=20)"),
animintLegendOptions=nuage1975+
theme_animint(width=500, height=500)+
theme(
legend.title=element_text(size=24),
legend.text=element_text(size=rel(2.5)))+
ggtitle("legend.text=element_text(size=rel(2.5)")))Cela vous permet de modifier la taille de la police tout en ajustant la taille du graphique, afin d’obtenir un rendu plus cohérent.
Notez que la taille de police par défaut dans animint2 est de 11px pour les axes et de 16px pour la légende.
Les options globales de la visualisation des données regroupent tous les éléments nommés de la liste vis qui ne sont pas des ggplots.
Le chapitre 3 a introduit l’option duration qui permet de spécifier la durée des transitions en douceur.
Le chapitre 3 a introduit l’option time qui permet de spécifier une variable de sélection qui est automatiquement mise à jour (animation).
Le chapitre 4 a introduit l’option first qui permet de spécifier la sélection lorsque la visualisation des données est générée pour la première fois.
Le chapitre 4 a introduit l’option selector.types qui permet de spécifier plusieurs variables de sélection.
title
L’option title doit être une chaîne de caractères définissant l’élément <title> de la page web. Il n’est pas utile d’utiliser l’option title dans un document Rmd tel que celui-ci. Un titre peut être utilisé avec animint2dir() comme dans le code ci-dessous.
vis.title <- vis.scale.size
vis.title$title <- "Plusieurs échelles de taille"
animint2dir(vis.title, "ch06-vis-title")Notez que vis.scale.size possède déjà trois ggplots, chacun avec son ggtitle. Ajouter l’option globale title a pour effet de définir un titre pour la page web.
Le chapitre 5 a introduit la fonction animint2pages() qui permet de publier une visualisation sur GitHub Pages. L’option title est nécessaire pour publier une visualisation dans une galerie.
L’option source doit être un lien vers le code source R qui a été utilisé pour créer la visualisation. Ce lien devrait être dans un dépôt différent que le dépôt que vous utiliser pour le déploiement dans animint2pages().
animint(
demo=ggplot()+
geom_point(aes(
Petal.Length, Sepal.Length),
data=iris),
source=paste0(
"https://github.com/animint/animint-manual-fr",
"/blob/main/chapitres/ch06/index.qmd"))Notez ci-dessus que le lien source figure au bas de la visualisation des données.
Le chapitre 5 a introduit la fonction animint2pages() qui permet de publier une visualisation sur GitHub Pages. L’option source est nécessaire pour publier une visualisation dans une galerie.
L’option video doit être un lien vers une vidéo qui montre des interactions possibles avec la visualisation. Ce mécanisme peut être utilisé pour faciliter la compréhension de ce qui est affiché et des interactions disponibles.
animint(
video="https://vimeo.com/1050117030",
scatter=ggplot()+
geom_point(aes(
x=espérance.de.vie, y=taux.de.fertilité, color=région),
clickSelects="pays",
alpha=0.7,
data=BanqueMondiale1975))Dans la visualisation de données ci-dessus, remarquez le lien video qui apparaît en bas à droite. En cliquant sur ce lien, on accède à une vidéo expliquant une visualisation de données plus complexe basée sur les données de la Banque mondiale. Vous pouvez enregistrer une vidéo pour chacun de vos animints, puis inclure un lien vers celle-ci à l’aide de ce mécanisme, afin que vos utilisateurs puissent comprendre plus facilement ce qui est affiché et quelles interactions sont possibles.
selectize
L’option selectize doit être une liste nommée de valeurs booléennes. Les noms doivent être des variables de sélecteur, et les valeurs doivent indiquer si vous souhaitez ou non générer un menu de sélection via selectize.js (Selectize-authors 2026). Par défaut, animint2 va générer un menu de sélection pour chaque variable de sélection, à deux exceptions près :
clickSelects et showSelected nommées ;
Ces valeurs par défaut devraient convenir à la grande majorité des animints. Pour voir un exemple du fonctionnement de l’option selectize, veuillez consulter le test PredictedPeaks (Hocking 2026).
Ce chapitre a expliqué plusieurs options de personnalisation des animints au niveau de l’observation, du geom, du graphique et au niveau global.
Exercices :
vis.chunk.vars avec différentes valeurs de chunk_vars pour les geom_point() et geom_segment(). Comment le choix des chunk_vars affecte-t-il l’apparence de la visualisation ? L’espace disque ? Le temps de chargement ?Le chapitre 7 explique les limites de l’implémentation actuelle de animint2.